Le guide ultime de la migration de données en Mendix

La sauvegarde et la restauration des données sont faciles lors de l'exécution Mendix candidatures dans le Mendix Cloud. C'est pourquoi j'aime développer avec le Mendix Plateforme. Il s'agit d'un service entièrement géré offrant un déploiement en libre-service en un clic avec CI/CD entièrement automatisé, journalisation avec options de sauvegarde et de restauration.
Cependant, il peut arriver un moment où vous décidez d'auto-héberger votre application, que ce soit sur Azure, AWS, voire même sur un Raspberry Pi ! Mendix prend en charge une multitude d'options de déploiement, des environnements traditionnels basés sur des machines virtuelles sous Linux et Windows aux nouvelles approches de conteneurisation avec Kubernetes ou Docker. Mais comment migrer les données d'une application d'un environnement à un autre ? C'est ce que je vais vous montrer dans cet article.
Dans cet article, je ferai référence à Source et Objectif environnements. Source étant l'environnement actuellement en cours d'exécution (celui dont nous voulons nous éloigner), et Objectif étant notre tout nouvel environnement auto-hébergé vers lequel nous souhaitons migrer les données.
Prétexte
Avant de commencer, il est important d’avoir une compréhension claire de la manière dont les données sont gérées et stockées par Mendix. Mendix sépare les données en deux : base de données et stockage de fichiers.
Base de données
La base de données reflète le modèle de domaine créé dans Studio Pro et stocke toutes les informations que vous attendez.
- Les entités sont mappées aux tables de base de données
- Les attributs correspondent aux colonnes des tables
- Les objets validés correspondent aux lignes de ces tables
In Mendix Cloud, c'est une base de données AWS Postgres.
Stockage de fichiers
Les fichiers, en revanche, sont stockés séparément. Les métadonnées relatives à un fichier (nom de fichier, taille, UUID) sont stockées dans la base de données, mais le contenu binaire du fichier lui-même ne l'est pas : le contenu binaire est stocké sous forme de stockage de fichiers. Les UUID dans la table de base de données FileDocument correspondent un à un aux noms de fichiers du contenu binaire. Mendix Cloud hébergé en tant que stockage d'objets sur AWS S3.
Introduction
Ce didacticiel porte sur la migration de données et de fichiers d'un environnement en direct. Il suppose que l'environnement cible est configuré, Mendix l'application est déployée, avec une base de données et un stockage de fichiers configurés (bien que vides) et fonctionnels.
Pour plus de détails sur la façon de déployer un Mendix candidature, vous pouvez consultez ce guide.
Avant d'entreprendre une migration sur une application de production en direct, il est judicieux de consulter cette liste de contrôle :
- L'environnement source et l'environnement cible exécutent-ils exactement la même version du Mendix application (.mda) ? (Ne pas utiliser la même version peut entraîner une perte de données)
- Une fenêtre de migration a-t-elle été planifiée et communiquée ? (La migration d'une application en ligne nécessite des temps d'arrêt, généralement en dehors des heures de bureau. Planifiez la migration et informez les utilisateurs lorsque l'application sera inaccessible.)
- Une date de capture instantanée a-t-elle été convenue et communiquée aux utilisateurs ? (Une migration nécessite de prendre un instantané de sauvegarde des données à un moment précis. Les modifications ultérieures ne seront pas migrées. Lorsqu'il est temps de migrer, arrêtez l'environnement en direct, prenez un instantané des données et commencez.)
- Entraînez-vous au processus de restauration dans un environnement jetable avant de le faire réellement pour vous assurer que vous êtes à l'aise avec les étapes.
- Créez un livre d'exécution pour documenter les étapes de la pratique auquel vous pourrez vous référer lors de la migration réelle.
Le livret d'exécution pourrait également inclure :
- Tests de fumée : cas de test exécutés après la migration pour confirmer le succès. (Un test pour valider que l'application contient les données attendues et confirmer que la base de données et le stockage de fichiers ont été migrés et synchronisés.)
- Étapes pour mettre à jour les enregistrements DNS et les équilibreurs de charge pour rediriger les utilisateurs vers le nouvel environnement cible.
- Un plan pour le pire des scénarios au cas où la migration échouerait ou si la fenêtre de migration allouée expirerait.
- Communications aux utilisateurs, parties prenantes, etc. en cas de scénarios différents.
Migration
As Mendix prend en charge une vaste gamme des types de bases de données, de stockage de fichiers et de déploiement, il existe également plusieurs approches de migration. Je vais vous montrer l'approche de migration la plus polyvalente, à l'aide de paramètres d'exécution personnalisés.
Dans cet exemple, je vais migrer une application exécutée sur Mendix Cloud vers mon nouvel environnement auto-hébergé fonctionnant dans Azure Kubernetes Service (AKS). Il exécute une base de données Azure SQL et Azure Blob Storage pour le stockage de fichiers.
A Mendix la migration nécessite deux parties : d'abord la migration de la base de données, puis ensuite du stockage des fichiers.
Paramètres d'exécution personnalisés
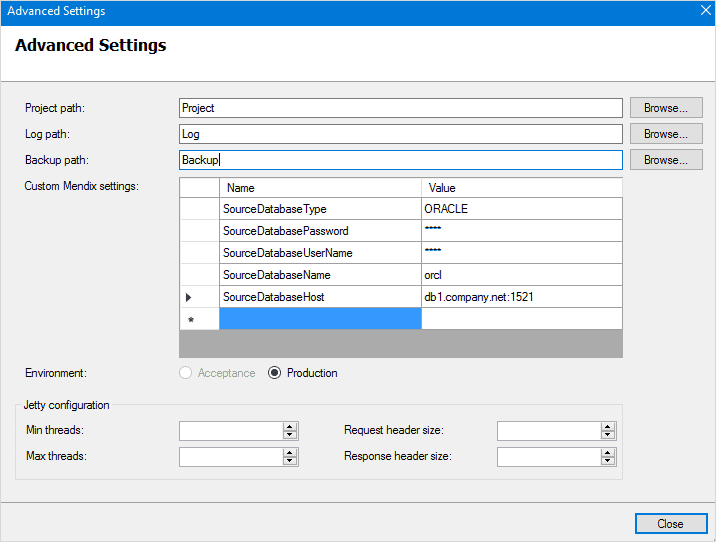
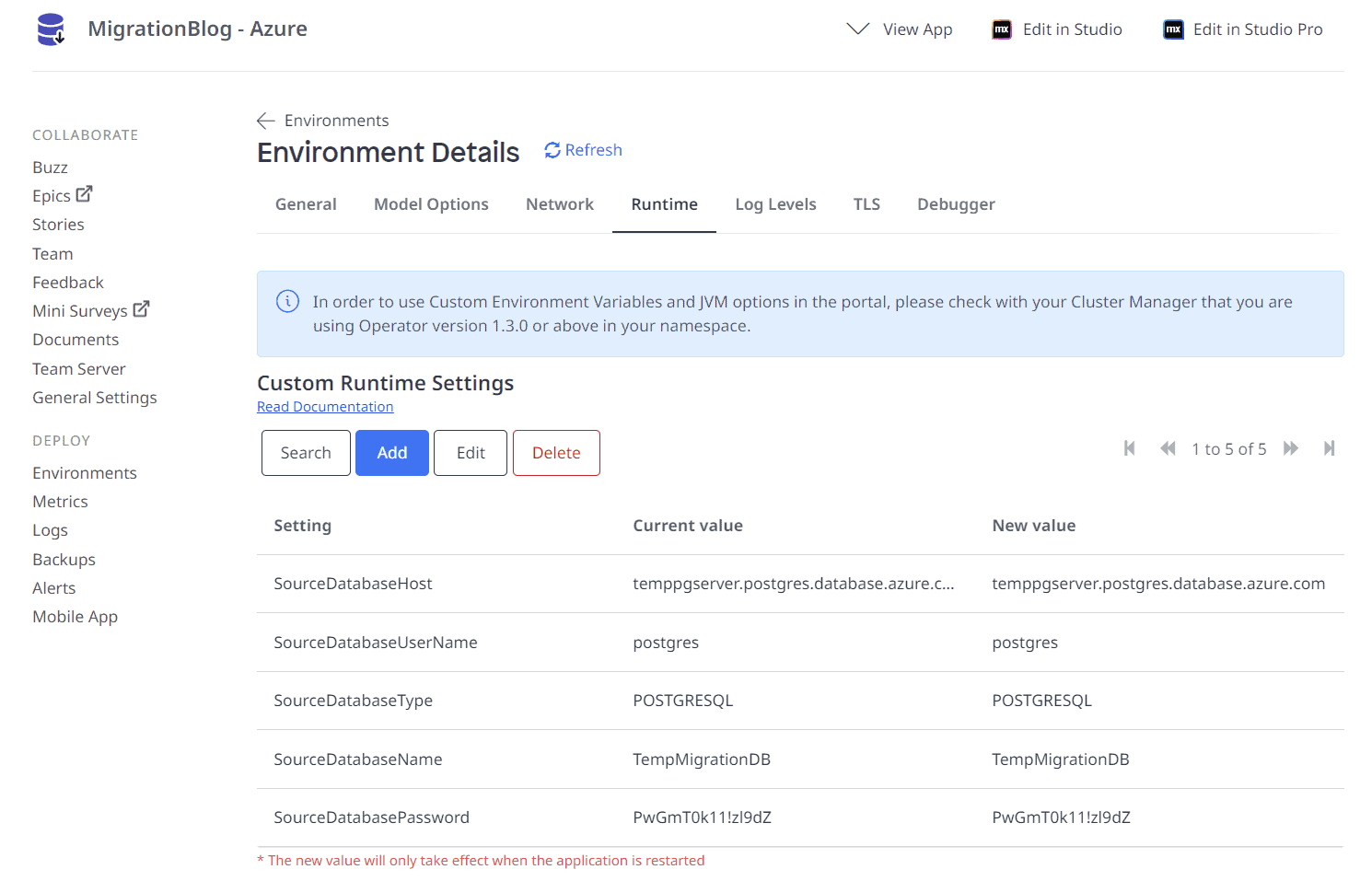
Mendix l'exécution dispose de fonctionnalités de migration intégrées via Paramètres d'exécution personnalisés. Ces paramètres transfèrent les données d'une base de données source vers une base de données cible. Ils convertissent également la base de données. Ainsi, si la base de données source est PostgresSQL et notre cible est MSSQL, le runtime s'en chargera pour nous.
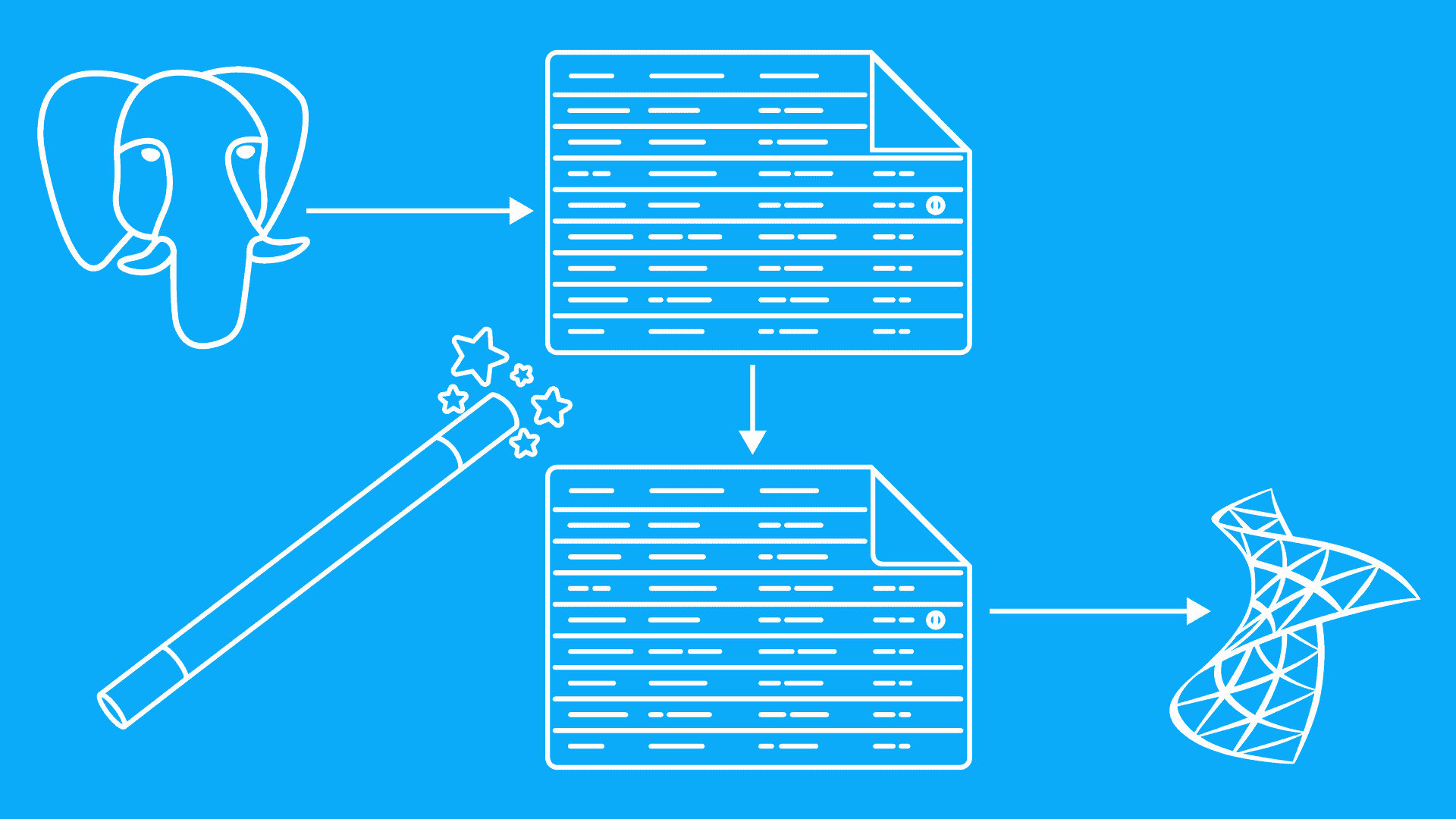
Les paramètres personnalisés les plus utilisés pour la migration de bases de données sont :
- Type de base de données source (HSQLDB, MYSQL, ORACLE, POSTGRESQL, SQLSERVER)
- SourceDatabaseHôte
- Nom de la base de données source
- Nom d'utilisateur de la base de données source
- Mot de passe de la base de données source
Notre nouvel environnement cible s'exécute dans Azure. Il nous suffit donc de configurer les paramètres d'exécution personnalisés comme indiqué ci-dessus, en pointant vers notre base de données source sur Mx Cloud, n'est-ce pas ?
Oui, cependant le Mendix Le cloud ne permet pas un accès direct à la base de données.
Par conséquent, nous devons créer notre propre base de données PostgresSQL temporaire, restaurer la sauvegarde Mx Cloud, puis utiliser cette base de données temporaire comme source dans les paramètres d'exécution personnalisés.
Si votre base de données cible est également PostGresSQL, aucune conversion, aucun paramètre d'exécution personnalisé ni aucune base de données temporaire ne sont nécessaires. Restaurez simplement la Mendix Sauvegarde dans le cloud directement sur votre base de données cible à l'aide de Fonctionnalités de restauration de PostgreSQL.
Vérifiez que la base de données cible et le stockage de fichiers sont vides
Le stockage du fichier cible et la base de données doivent être vides avant d'effectuer une migration.
Peut-être avez-vous commencé votre objectif Mendix application, a effectué des tests pour confirmer son fonctionnement et a ainsi créé des données par inadvertance. Cela doit être supprimé avant la migration.
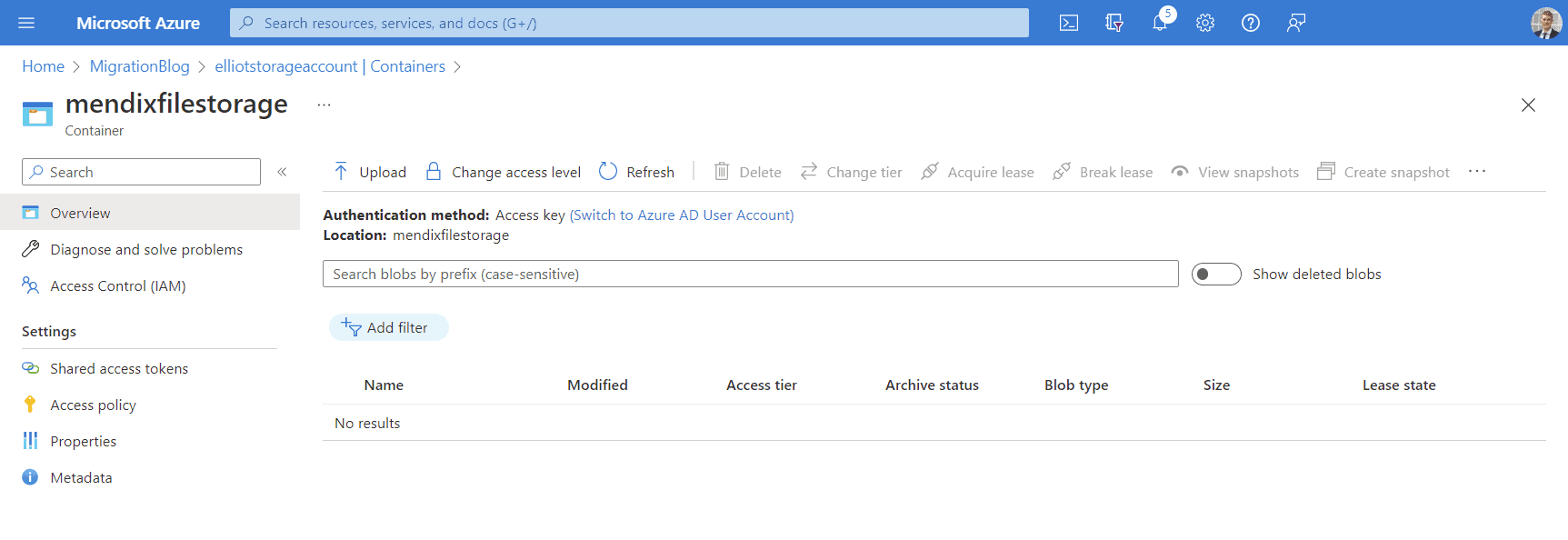
Stockage de blog Azure (cible)
Azure SQL Server (cible)
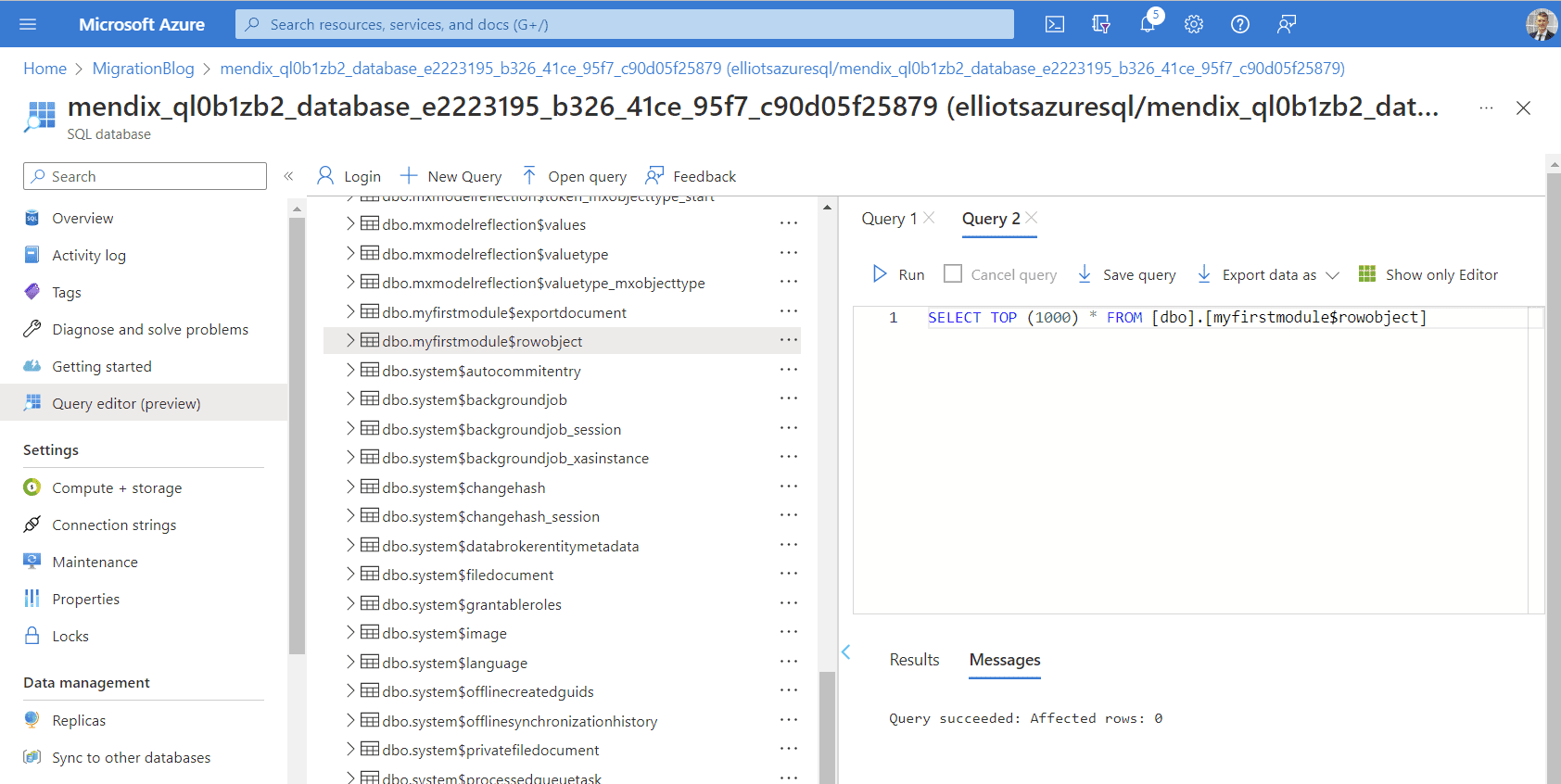
Ma base de données cible n'est pas vide. Elle contient les tables d'application qui doivent être supprimées pour que la migration fonctionne.
J'ai écrit un rapide Fonction Excel pour écrire les commandes SQL nécessaires pour supprimer toutes les tables, sans quitter le navigateur.
Une alternative aurait pu être Studio de gestion SQL Server (SSMS) qui dispose d'une interface graphique visuelle pour déposer des tables en quelques clics.
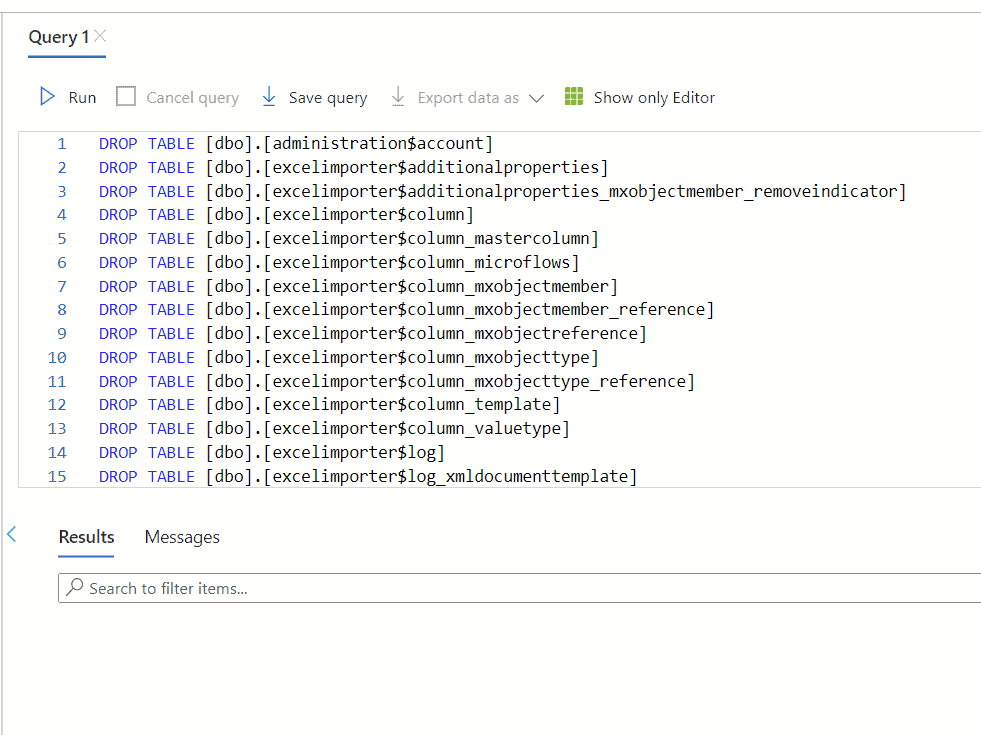
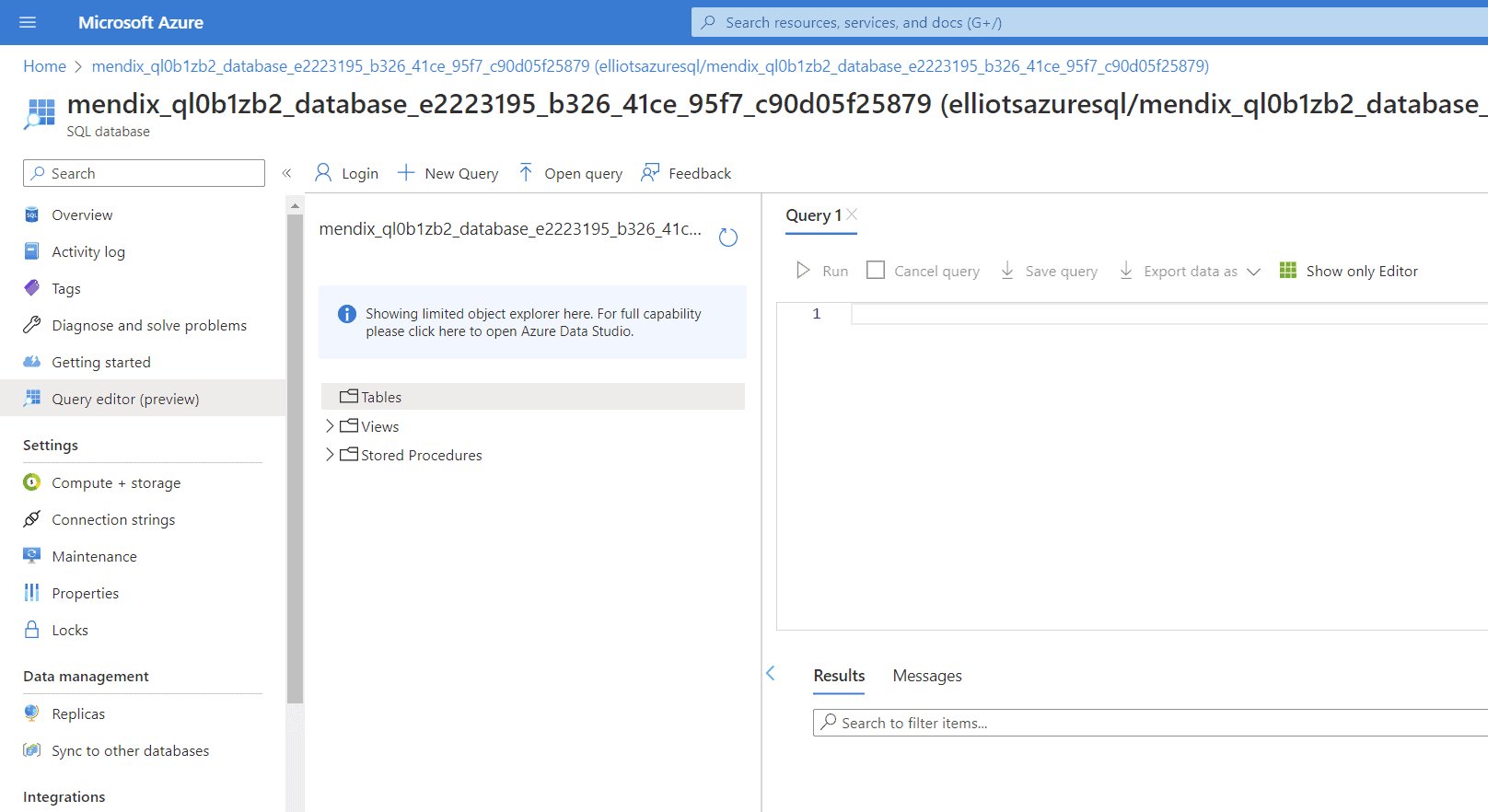
Après avoir exécuté ces commandes, ma base de données est vide.
Prenez l'instantané 📸
Il est temps de faire la sauvegarde finale de nos données de production et de commencer la migration. Mendix Le cloud est en libre-service, il est donc facile de le mettre en œuvre.
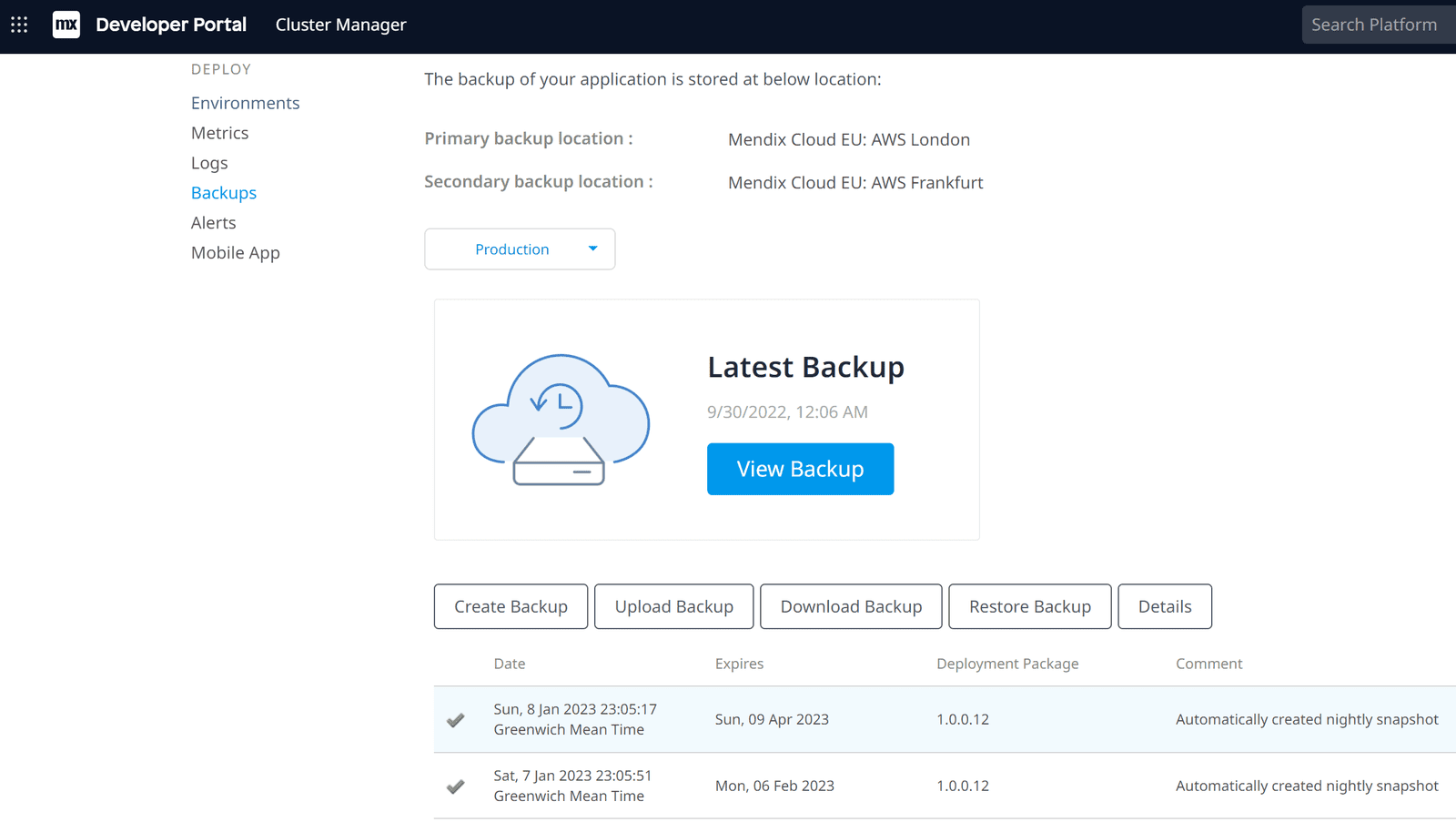
Extrait du Mendix Portail des développeurs Cloud :
- Sauvegardes > Production > Créer une sauvegarde (Mendix crée un instantané de vos données)
- Télécharger la sauvegarde > Instantané complet (Selon la taille de votre application, cela peut prendre de quelques minutes à plusieurs heures.)
Un instantané complet contient une archive compressée *.tar.gz, qui est extractible à l'aide de 7-zip sous Windows.
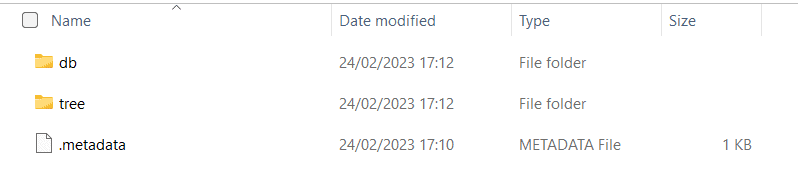
La structure du dossier est la suivante :
- db – La sauvegarde de la base de données postgres
- arbre – Le stockage de fichiers
La base de données temporaire PostgresSQL
Créer une base de données PostgresSQL. Il s'agit d'une solution temporaire pour obtenir une base de données que nous contrôlons et pour laquelle nous disposons des détails de connexion.
Étant donné que mon environnement cible est dans Azure, je vais créer un serveur de base de données Azure Postgres.
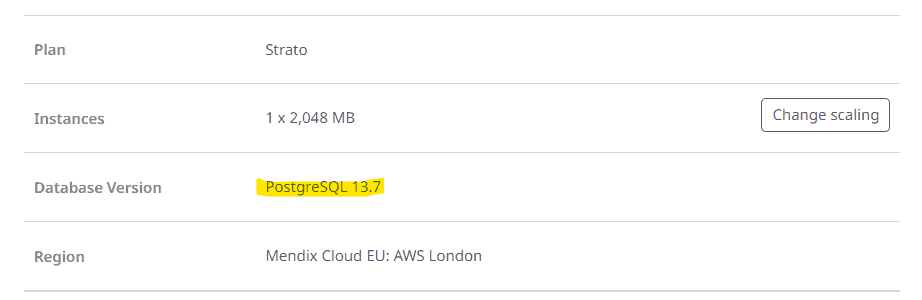
Remarque : l’environnement cible nécessite une connectivité réseau à la base de données temporaire pour migrer les données.
Assurez-vous que la base de données PostGresSQL temporaire est la même version que votre base de données source (trouvée dans la page des détails de l'environnement du portail des développeurs Mx).
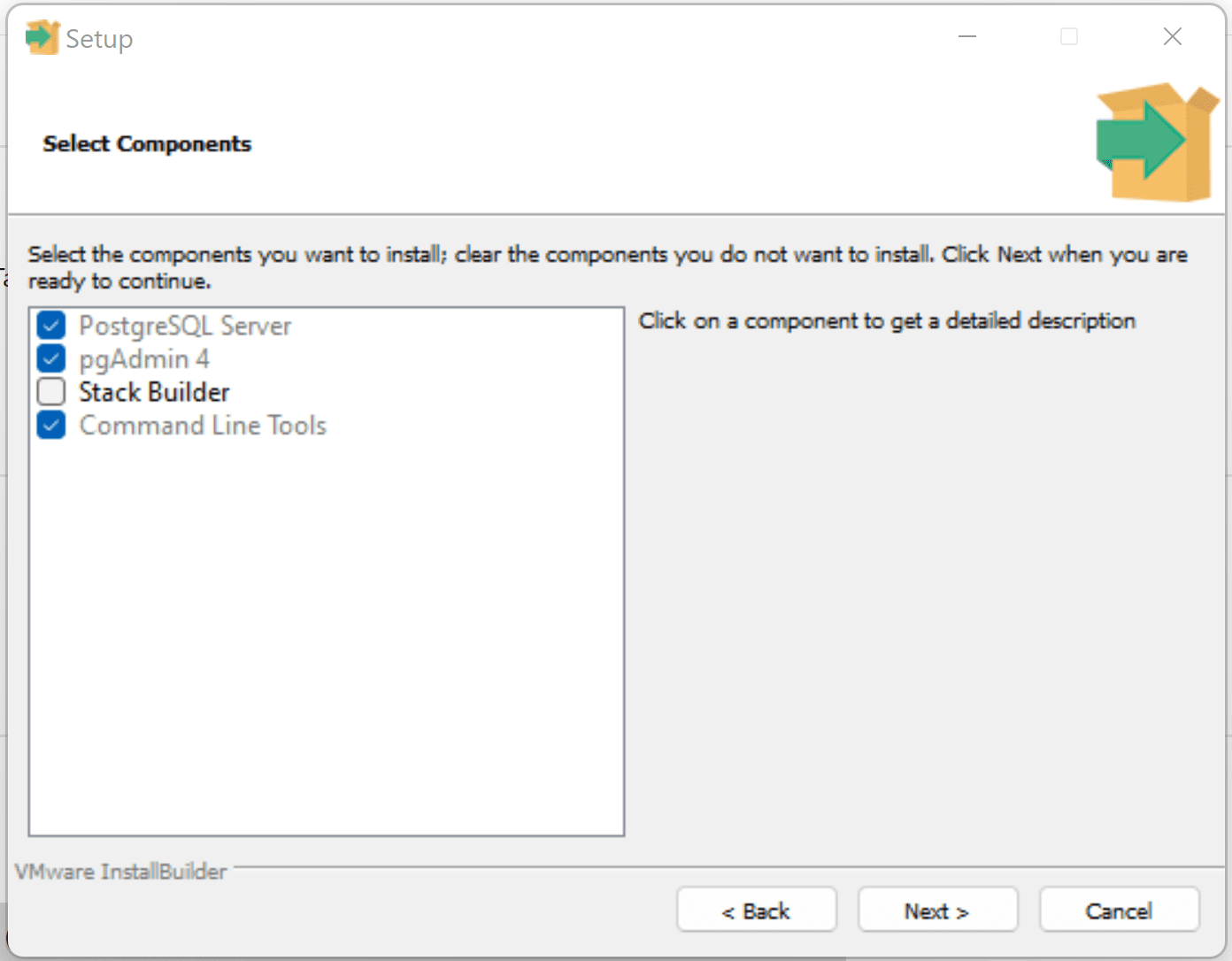
Pour effectuer la restauration, nous devons pouvoir interagir avec notre base de données temporaire nouvellement créée. Je vais installer pgAdmin 4 car cela donne une interface graphique simple :
Téléchargez et installez Postgres sur votre machine locale
(PostgreSQL : Téléchargements) Assurez-vous que pgAdmin et PostgreSQL Server sont sélectionnés (requis pour la fonction de restauration).
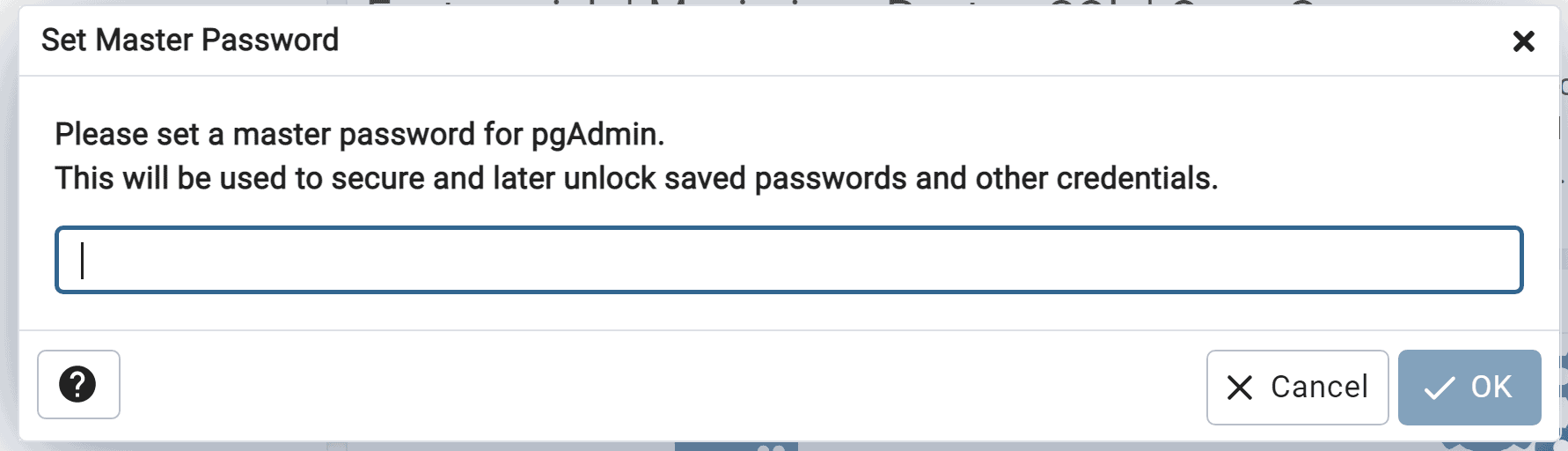
Définir un mot de passe principal au premier démarrage de pgAdmin
Connectez-vous à notre serveur Azure PostgresSQL en utilisant les détails de connexion

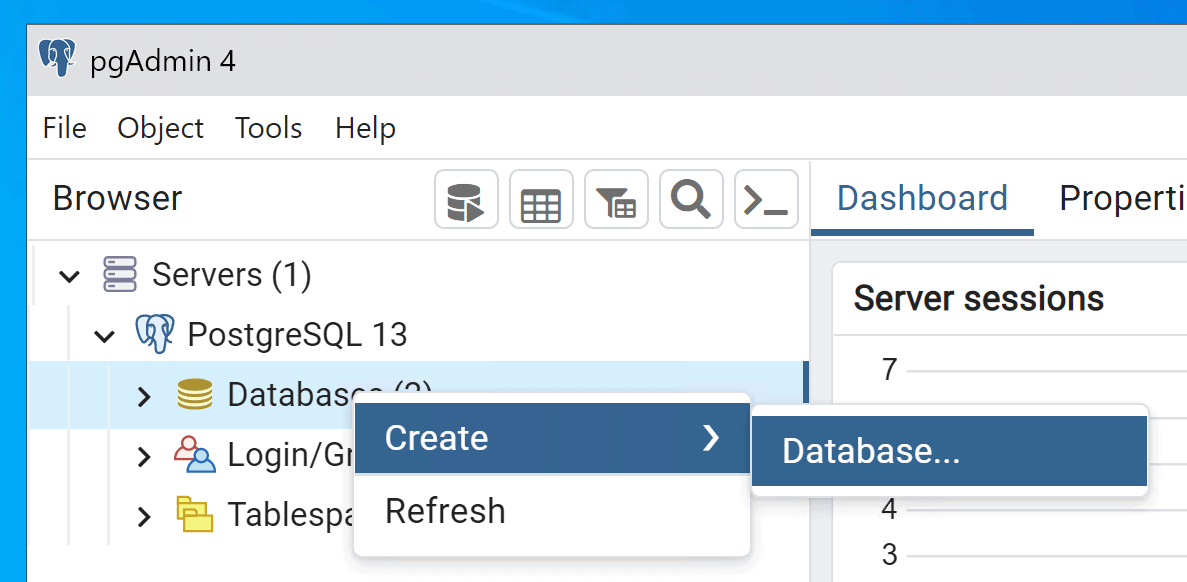
Créer une base de données temporaire
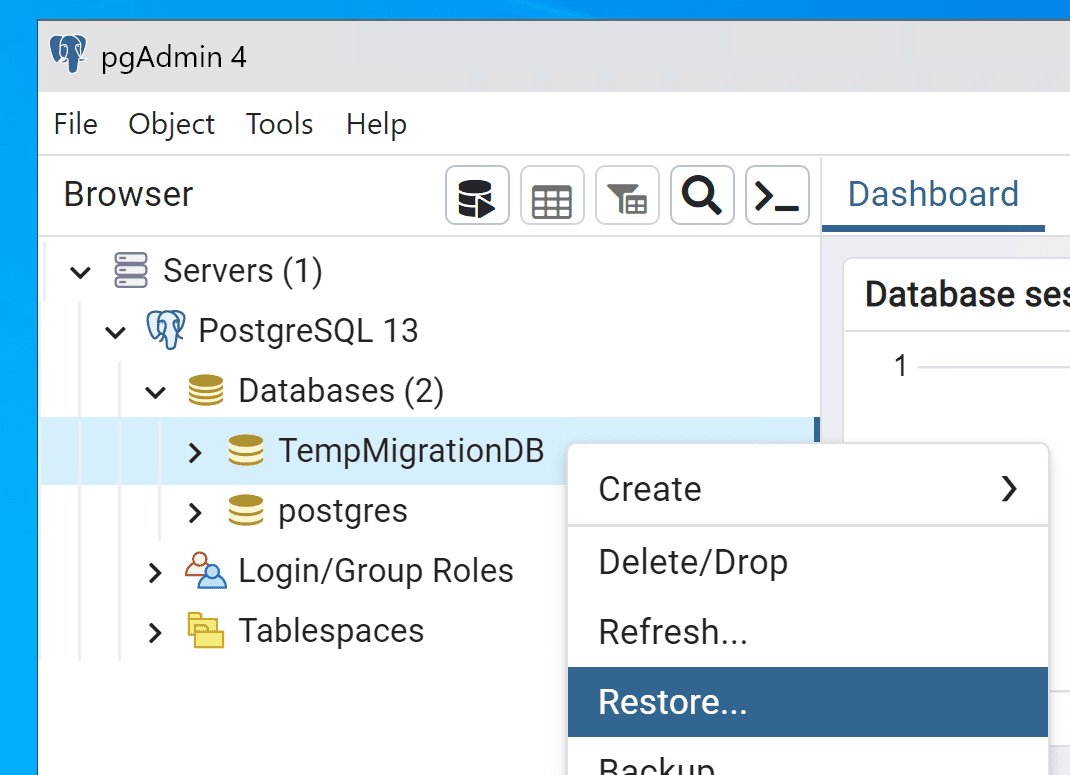
Restaurer la sauvegarde
La restauration vers PostGresSQL est simple.
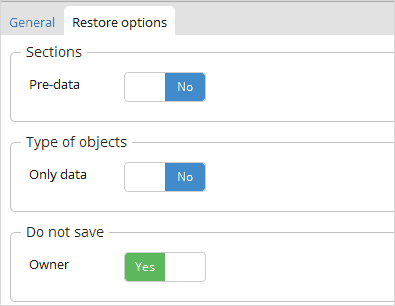
Sélectionnez simplement votre fichier de sauvegarde « db.backup », en vous assurant que « Ne pas enregistrer le propriétaire » est défini sur =true.
Plus de détails ici.
Valider la restauration de la base de données temporaire
Nos données sont ici, la restauration dans notre base de données temporaire a réussi.
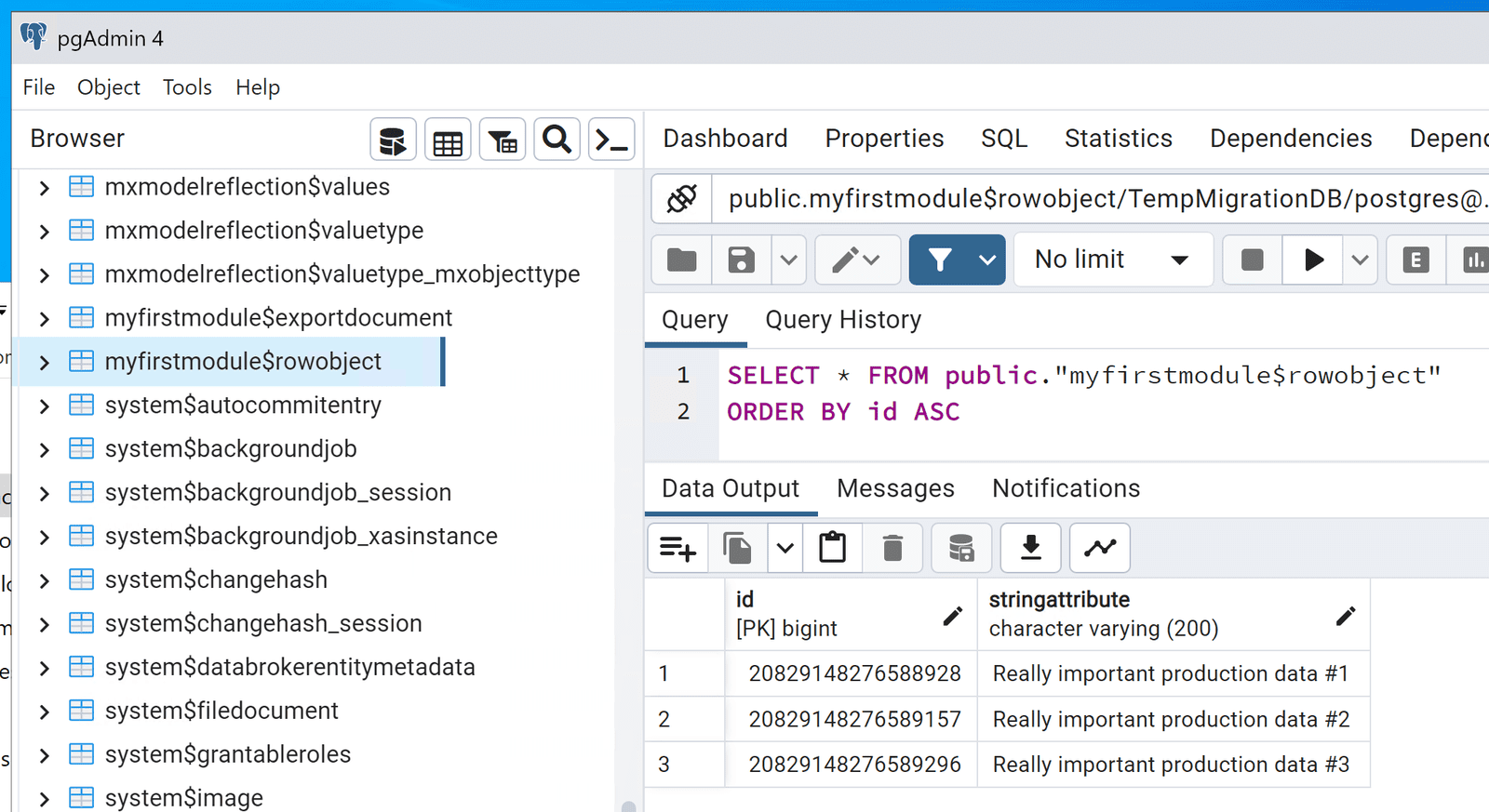
Nous avons maintenant nos données de production dans une base de données que nous contrôlons et nous disposons des détails de connexion !
Migrer la base de données
Les migrations de Postgres vers Postgres sont donc extrêmement faciles. Si votre base de données cible est PostgresSQL, vous pouvez simplement suivre les étapes ci-dessus directement dans votre base de données cible.
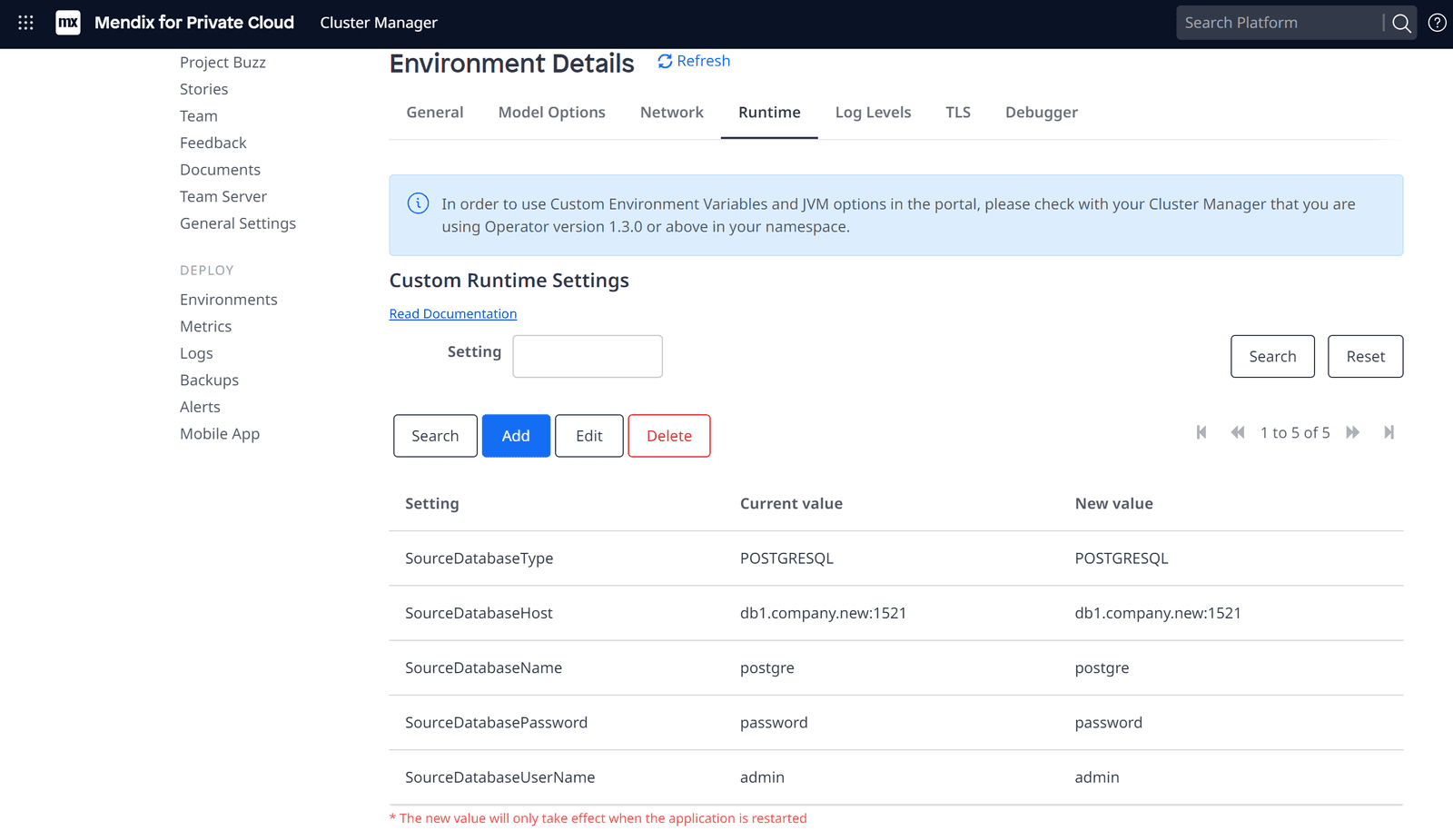
Pour ma part, je dois effectuer une conversion et une migration vers MS SQL Server (Azure SQL). Heureusement, nous pouvons le faire via des paramètres d'exécution personnalisés.
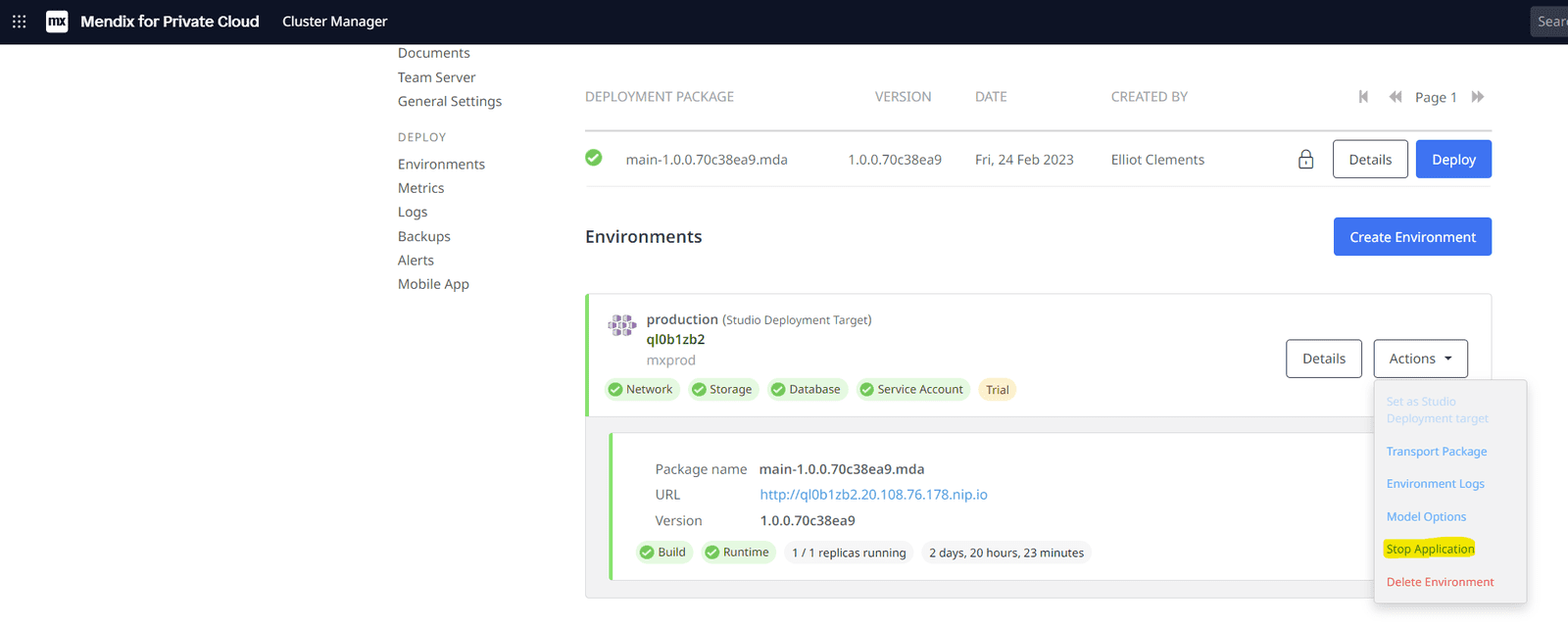
Assurez-vous que l'application cible est arrêtée
Définir les variables d'exécution personnalisées
Démarrez l'environnement cible et vérifiez que la restauration de la base de données a fonctionné
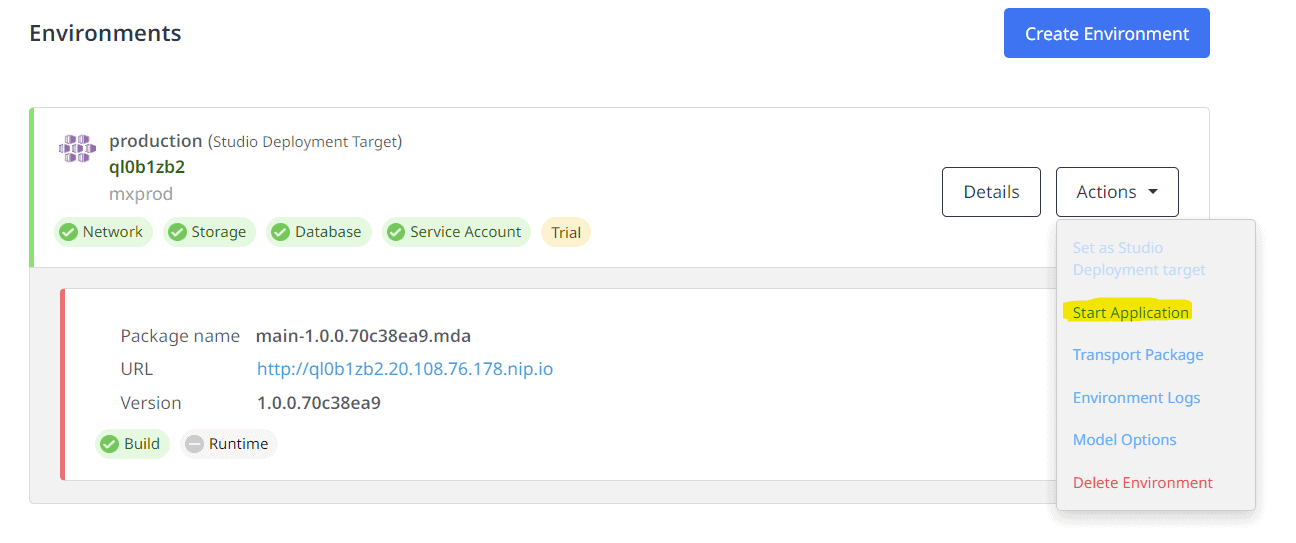
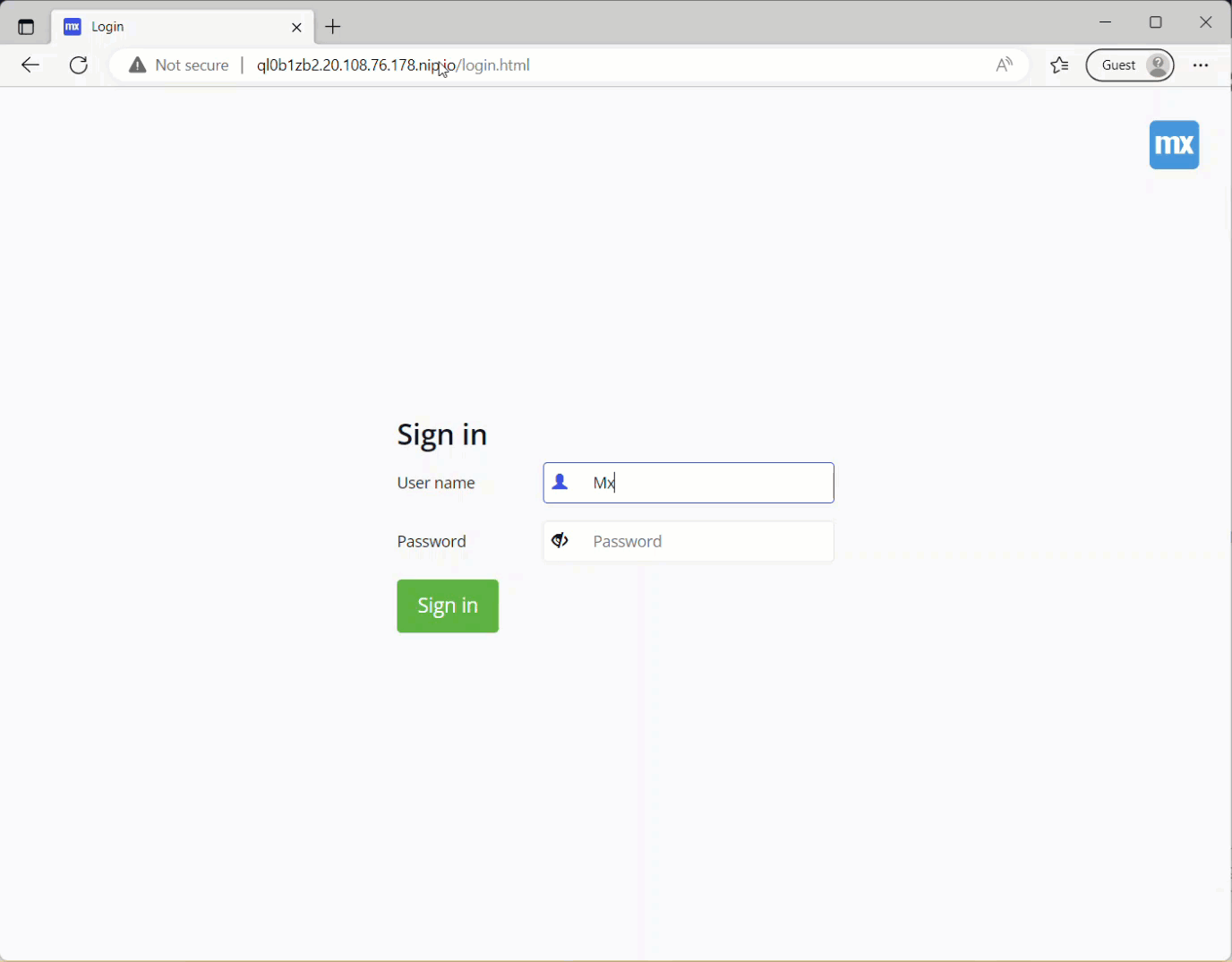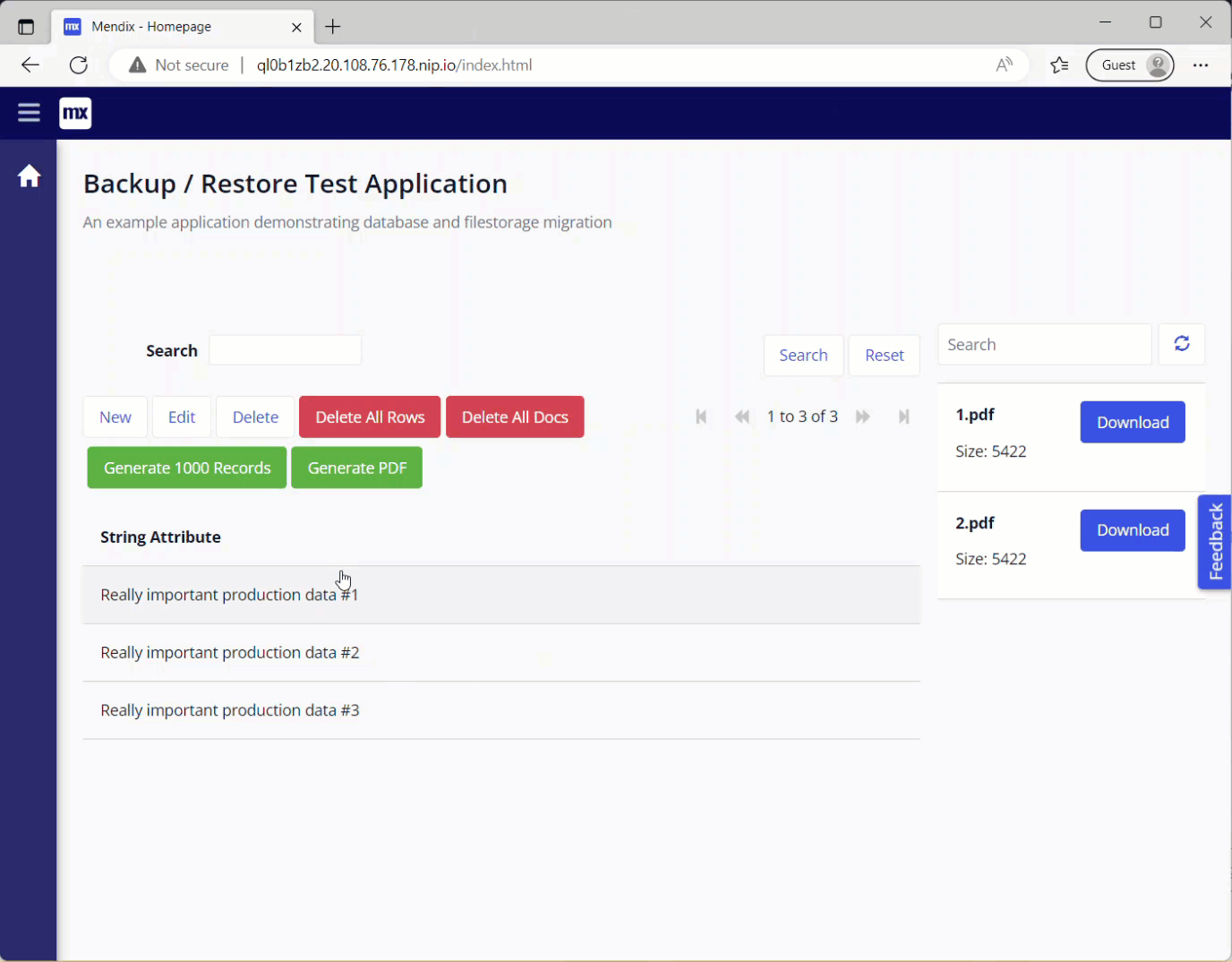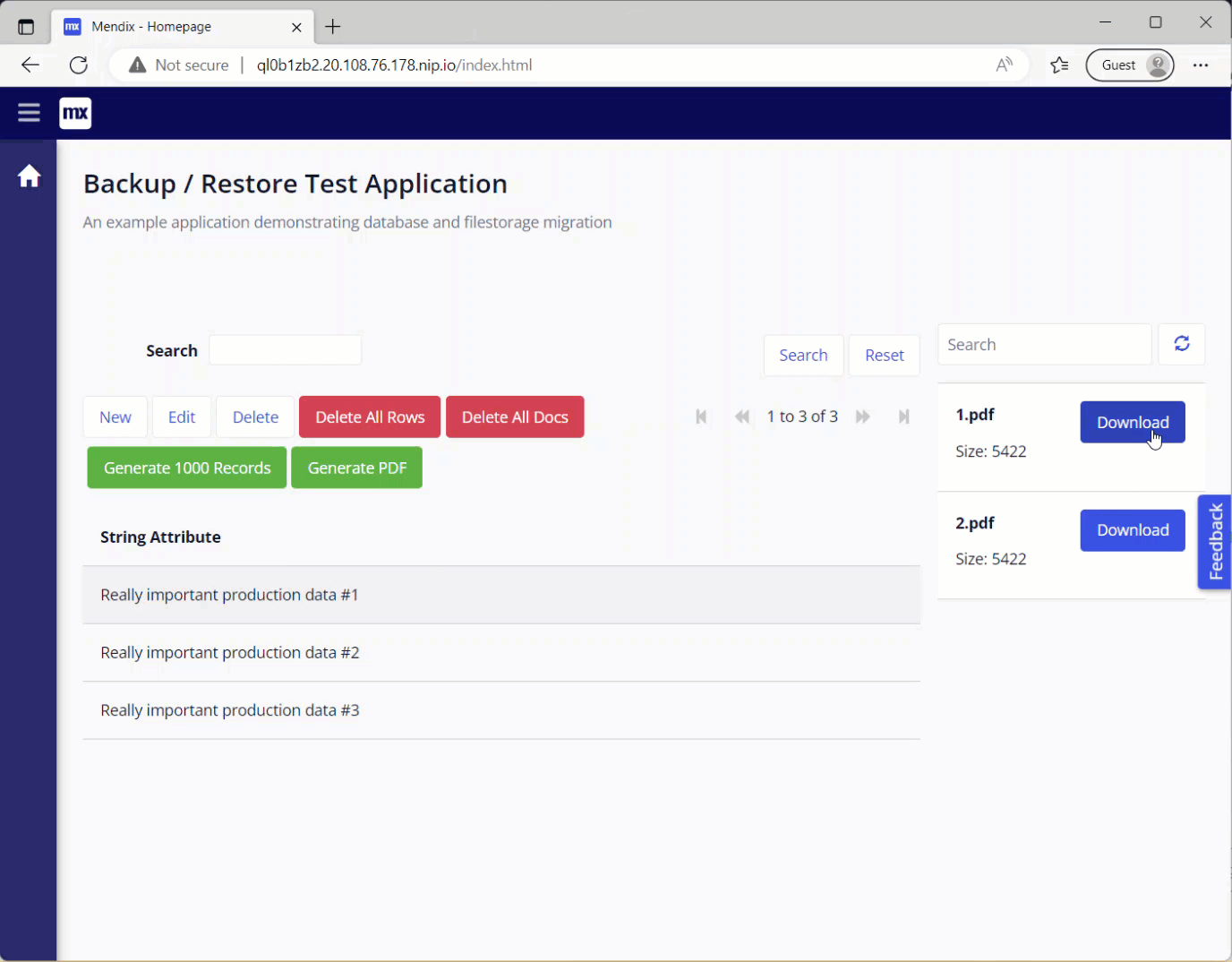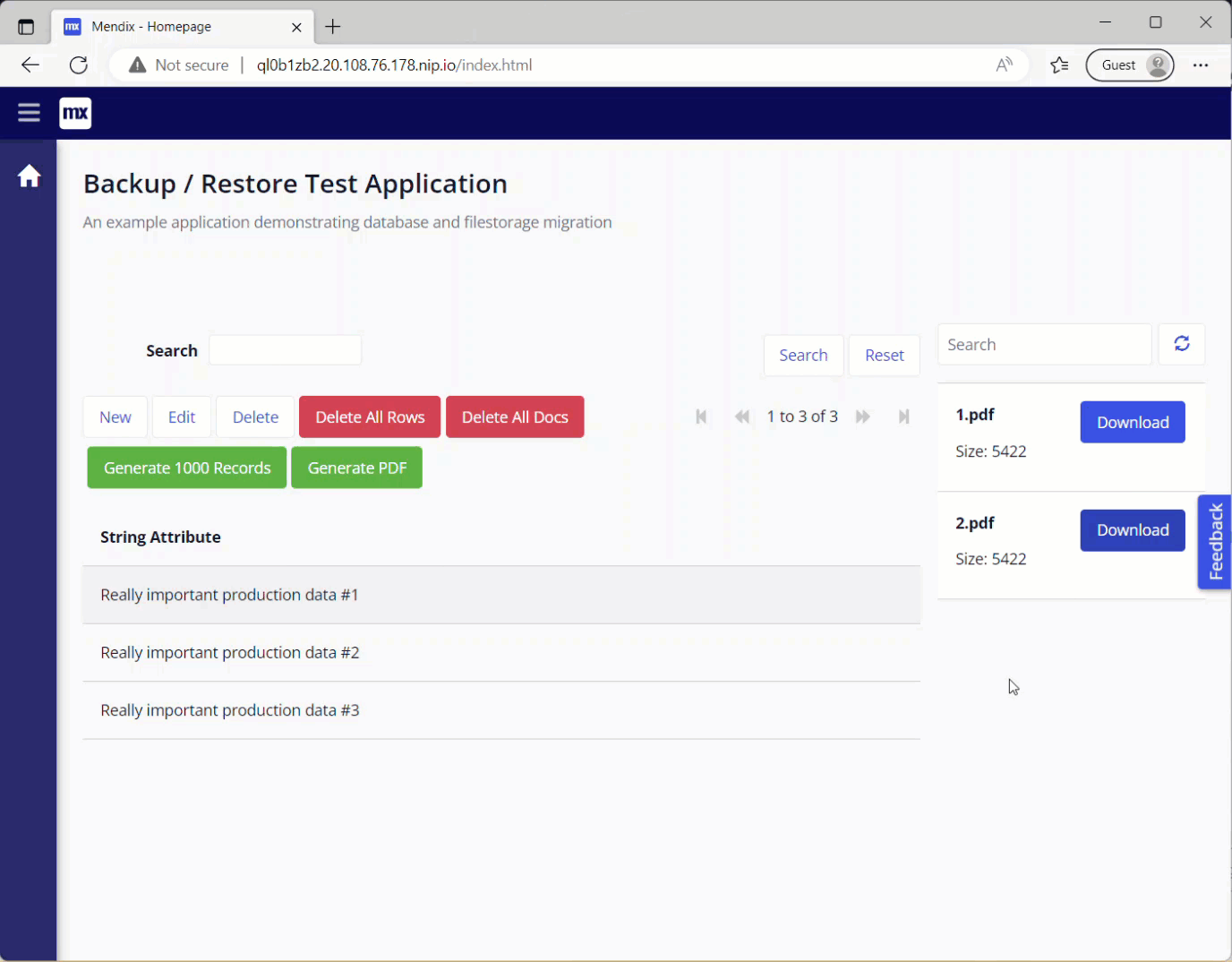
Les données ont migré avec succès.
Mais attendez, les documents du fichier s'affichent mais ne se téléchargent pas. Cela est dû au fait que nous avons restauré la base de données, qui contient les métadonnées, mais que nous n'avons pas encore migré le stockage des fichiers.
Migrer le stockage de fichiers
Il s’agit de la plus simple des deux migrations. Il nous suffit de télécharger les fichiers de notre instantané vers le stockage de fichiers cible, qui dans mon cas est Azure Blob Storage.
Aplatir la structure du dossier (si nécessaire)
La prise en charge du stockage d'objets blob Azure dans Mendix s'attend à ce que tous les objets soient disponibles dans un dossier. Par conséquent, je dois aplatir et stocker tous les fichiers dans un répertoire racine. Comme je suis un utilisateur Windows, je vais utiliser un simple Script PowerShell pour cela.
Get-ChildItem -Path SOURCE -Recurse -File | Move-Item -Destination DEST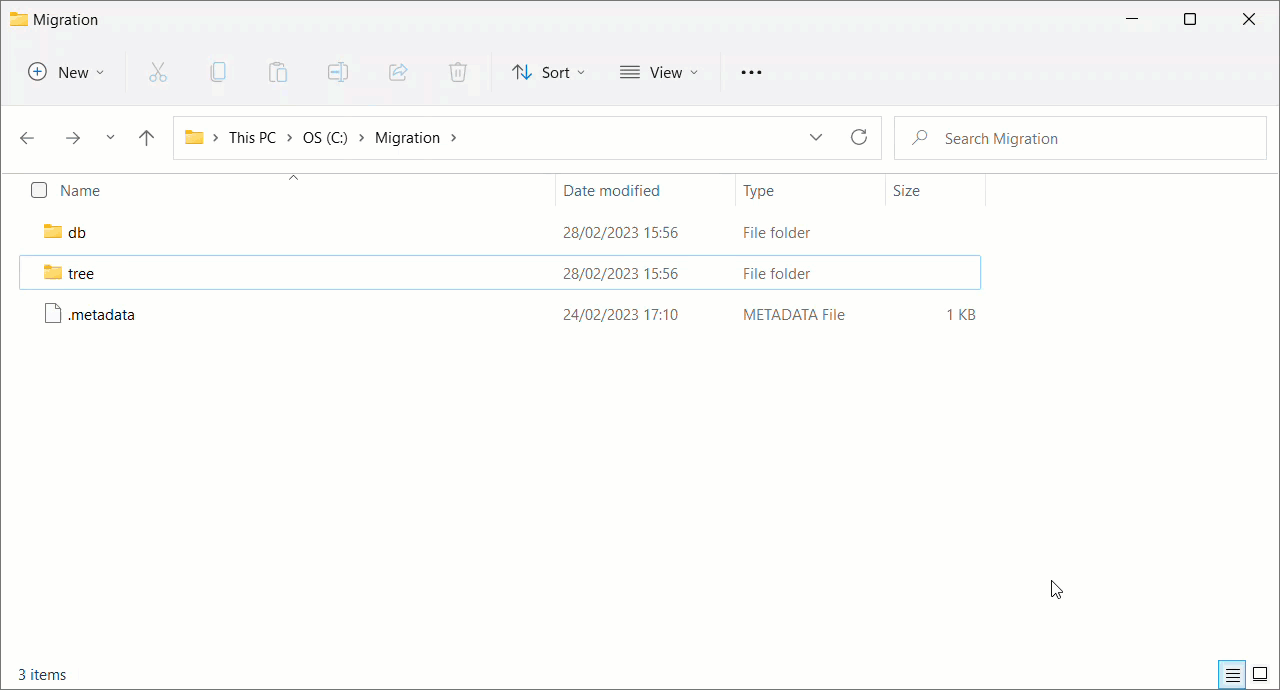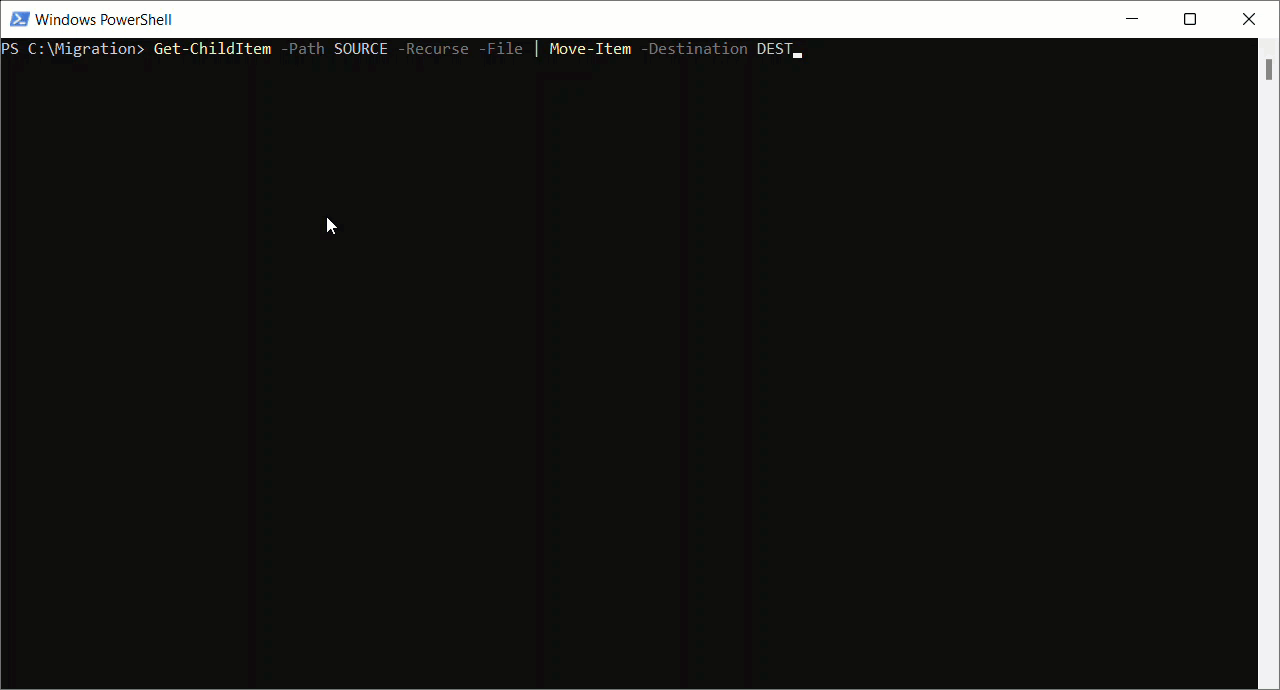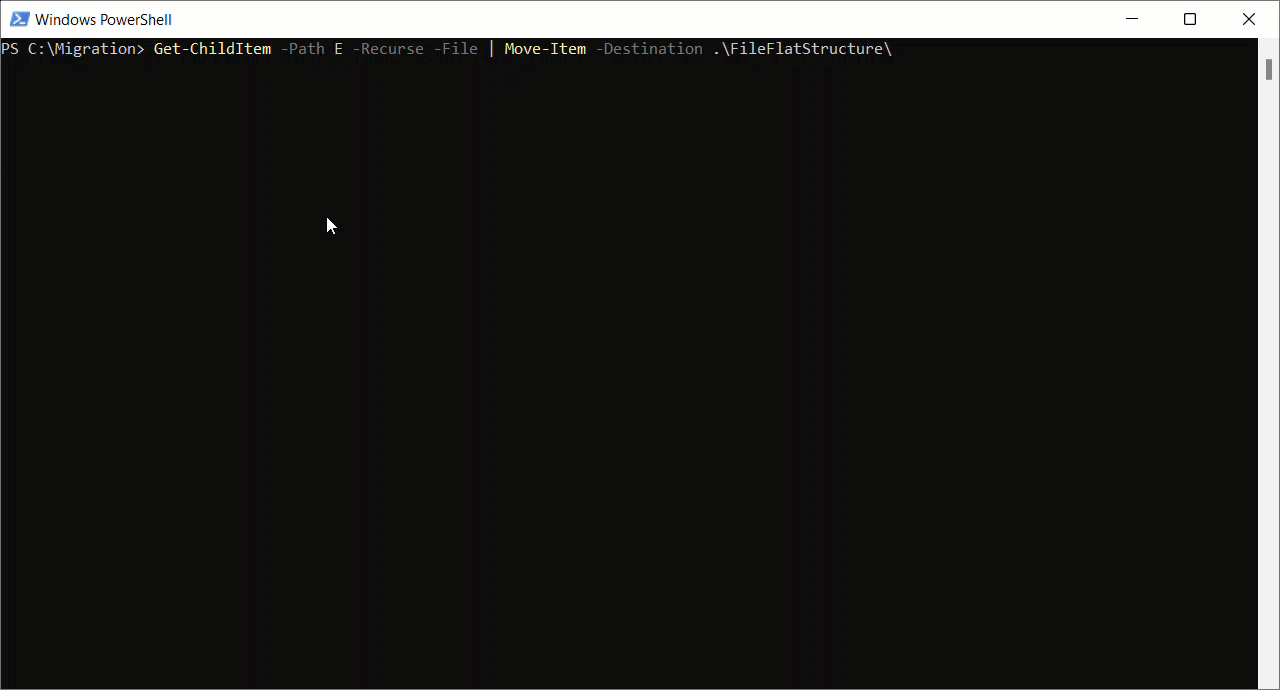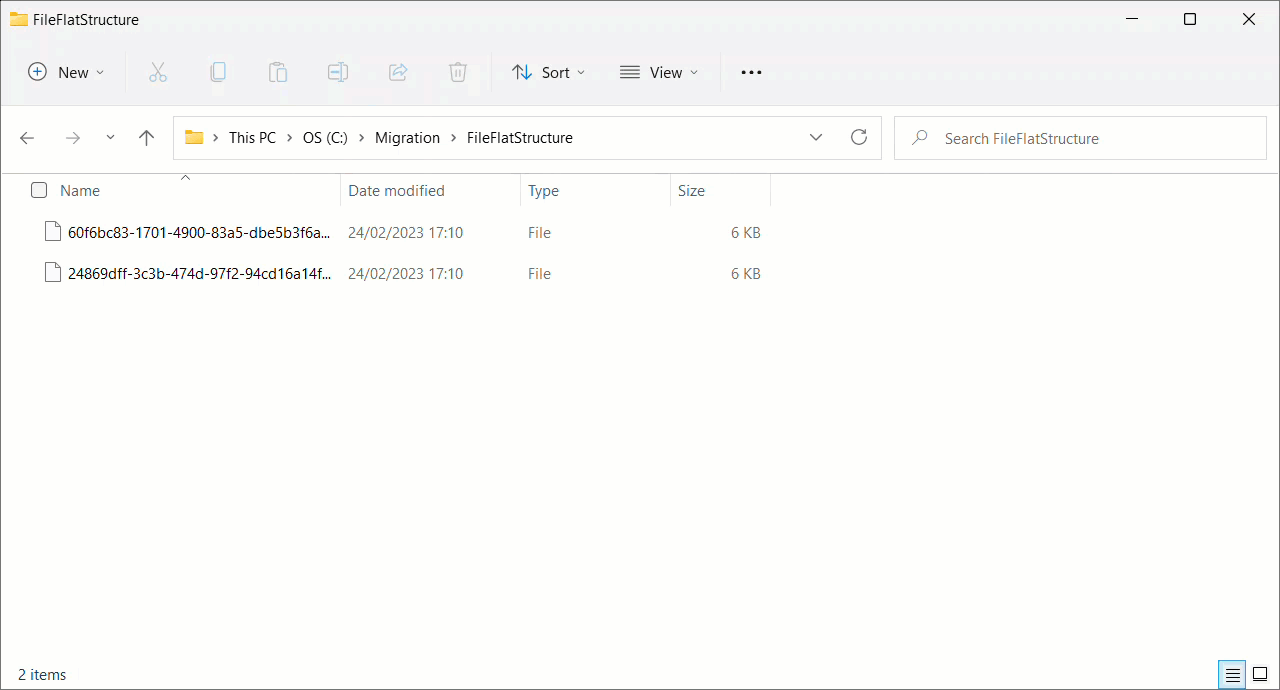
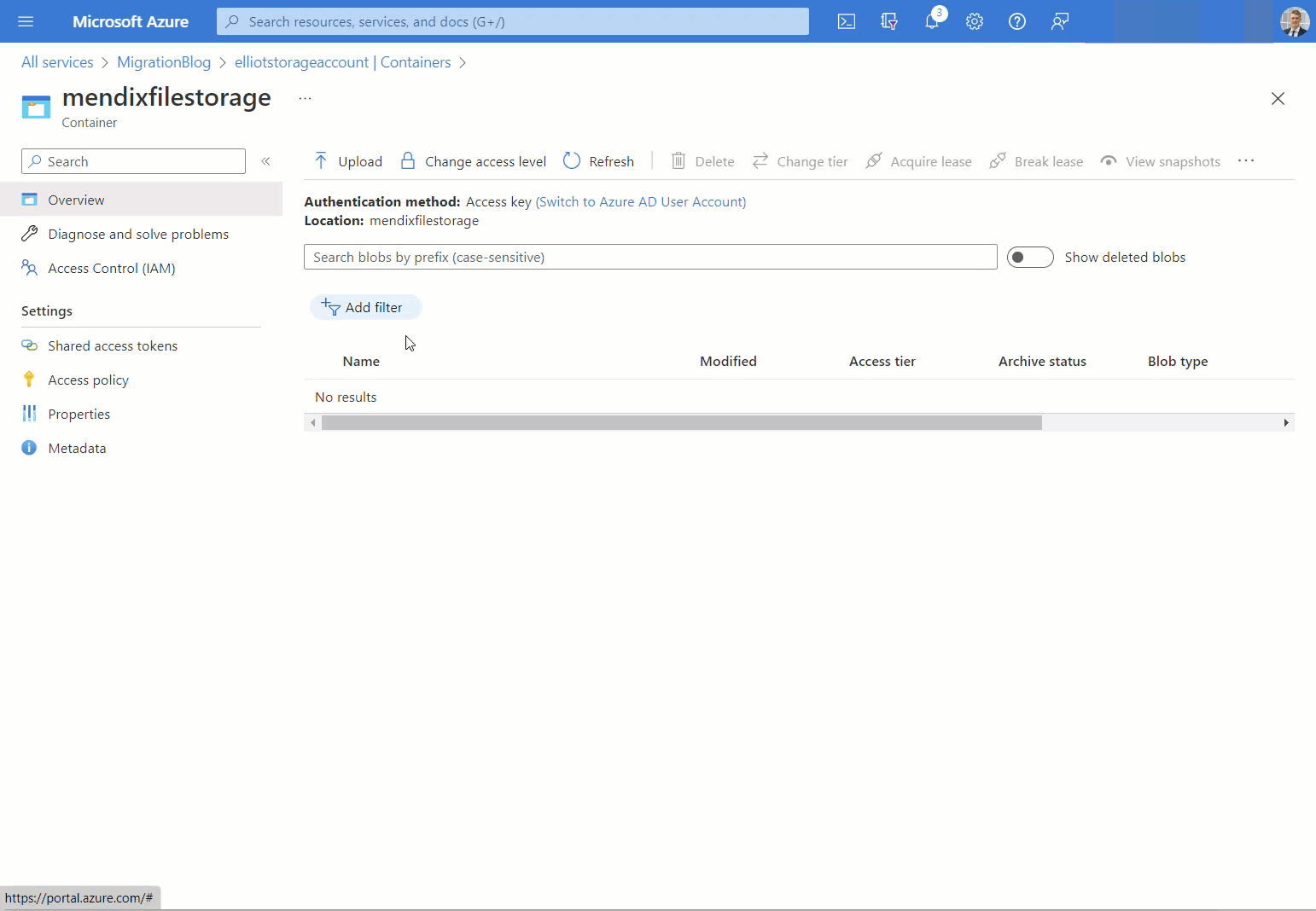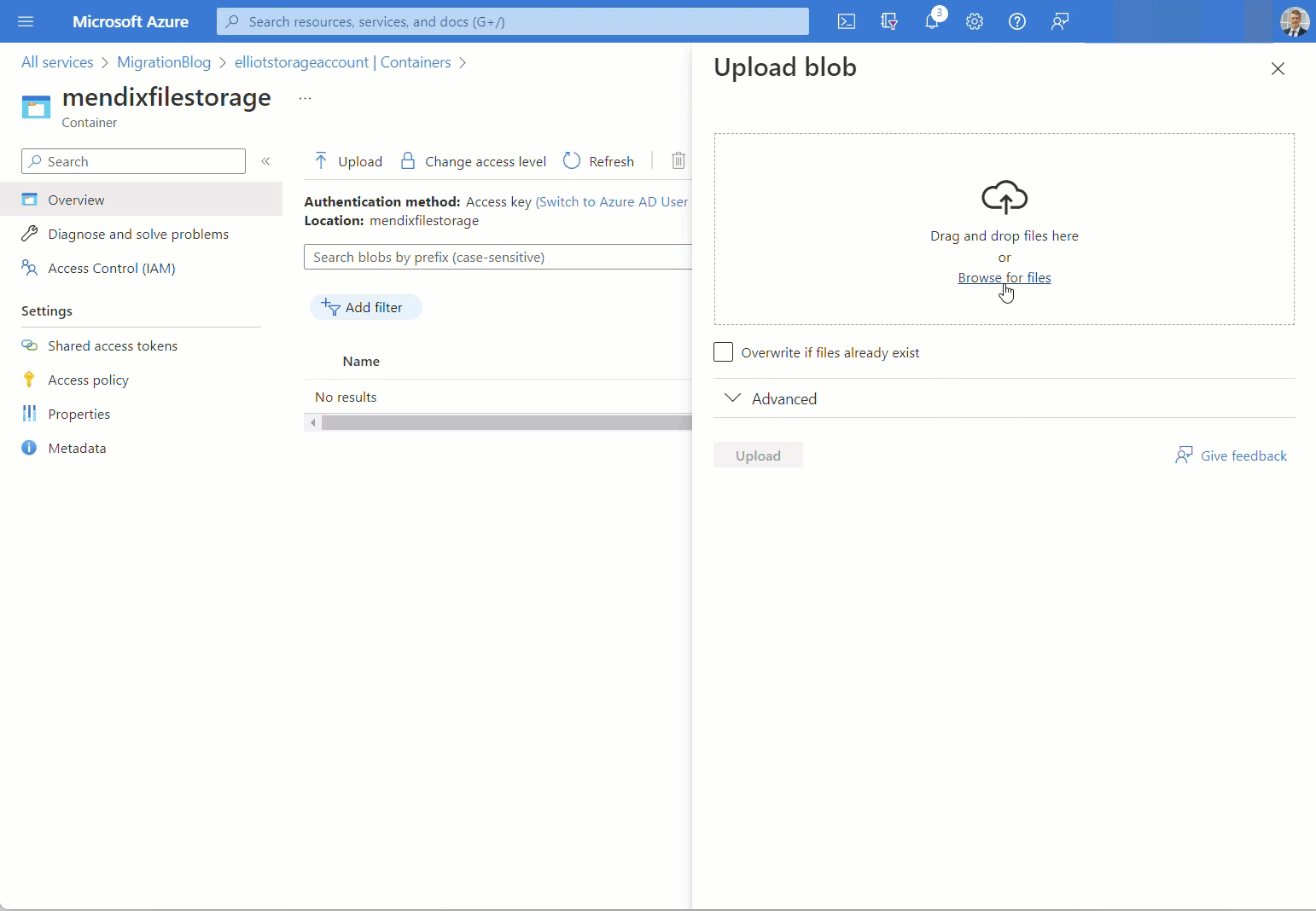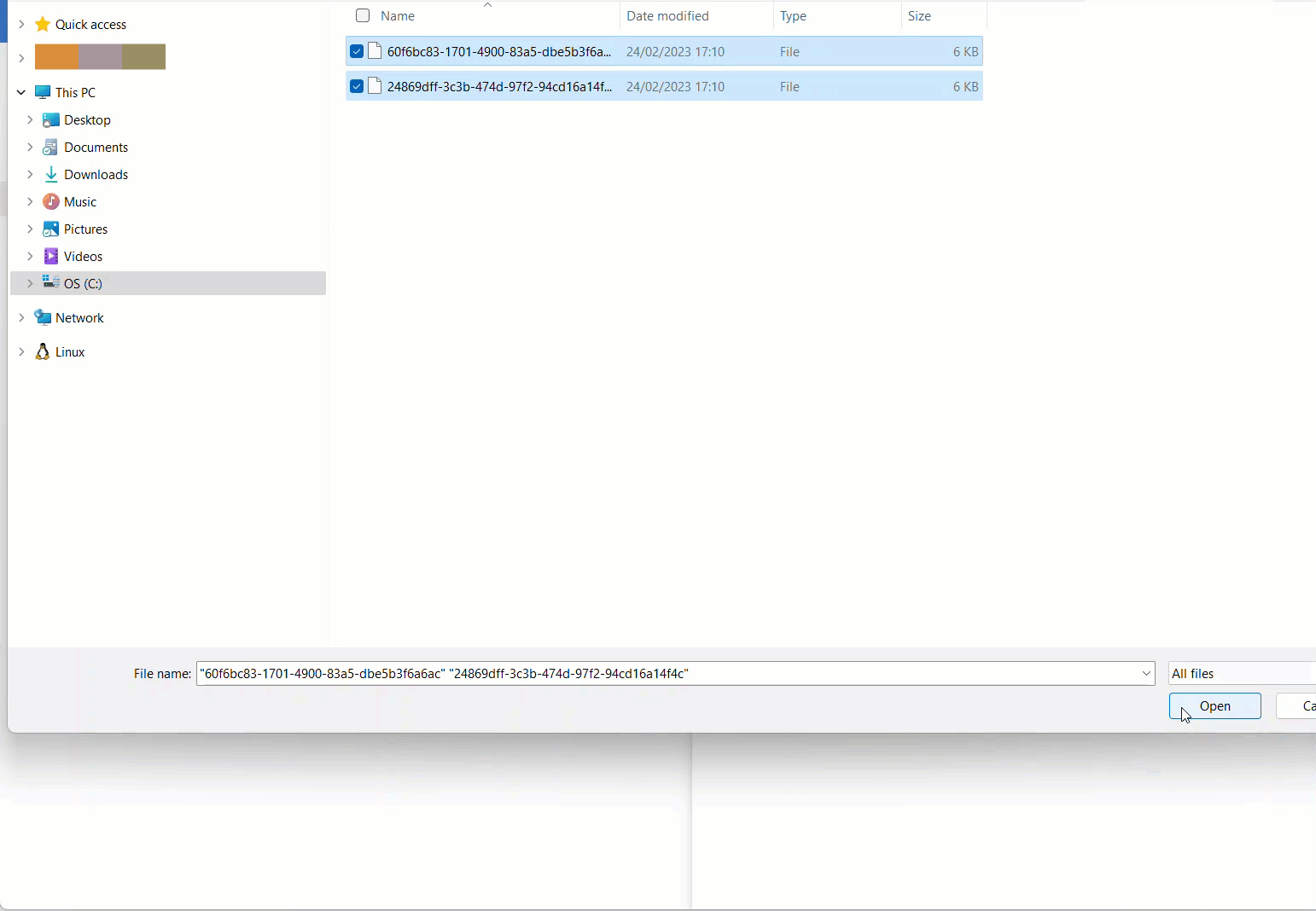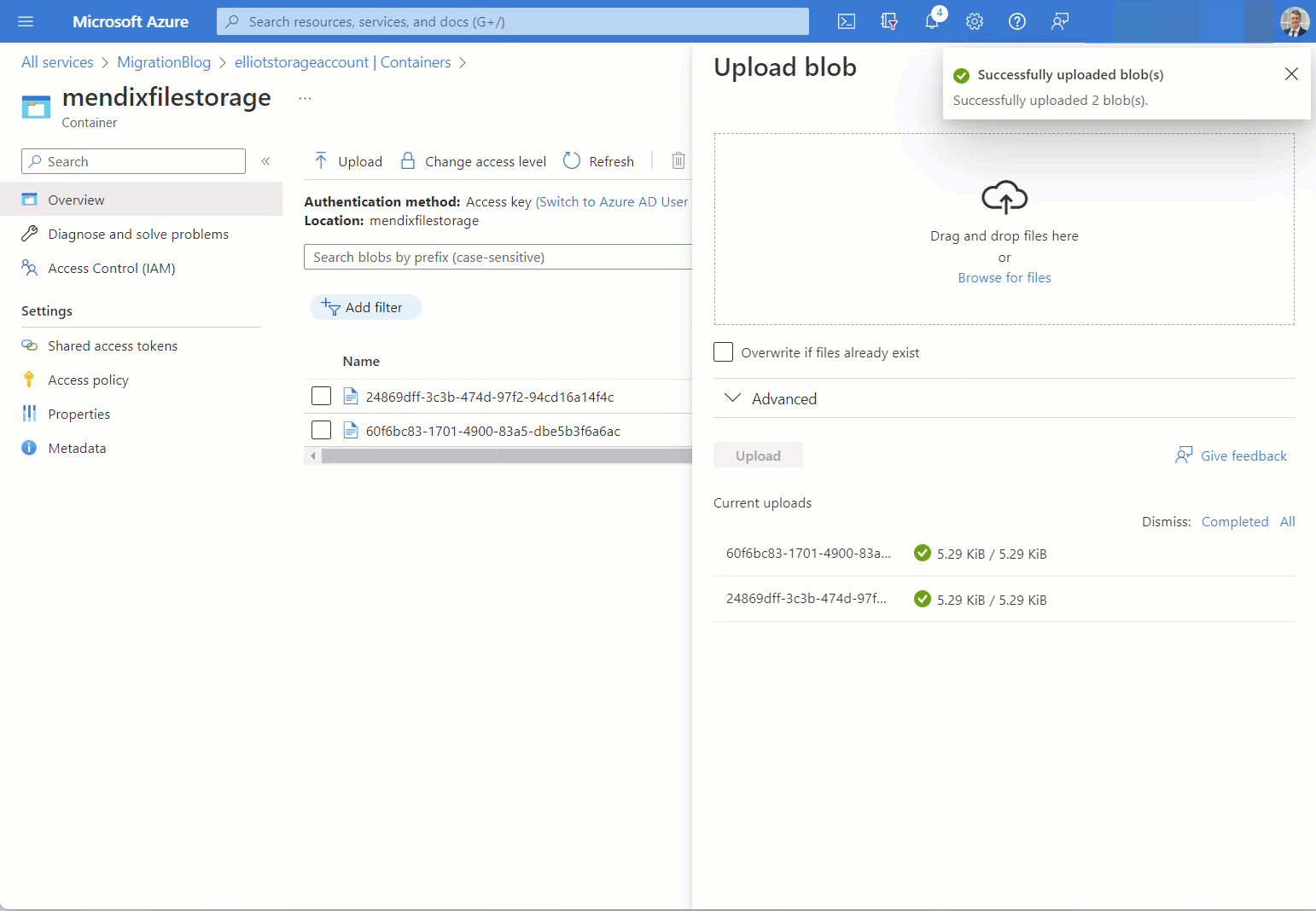
Télécharger des fichiers vers le conteneur de stockage d'objets blob Azure
Pour les migrations plus importantes, avec des milliers de fichiers représentant plus de 100 Go, vous préférerez peut-être utiliser CLI Azure or Explorateur de stockage Azure.
Dans mon scénario, je n’ai que deux fichiers, je vais donc utiliser le portail Web Azure.
Test de fumée
En exécutant à nouveau l’application, j’ai maintenant un accès complet à mes données et au contenu de mes fichiers !
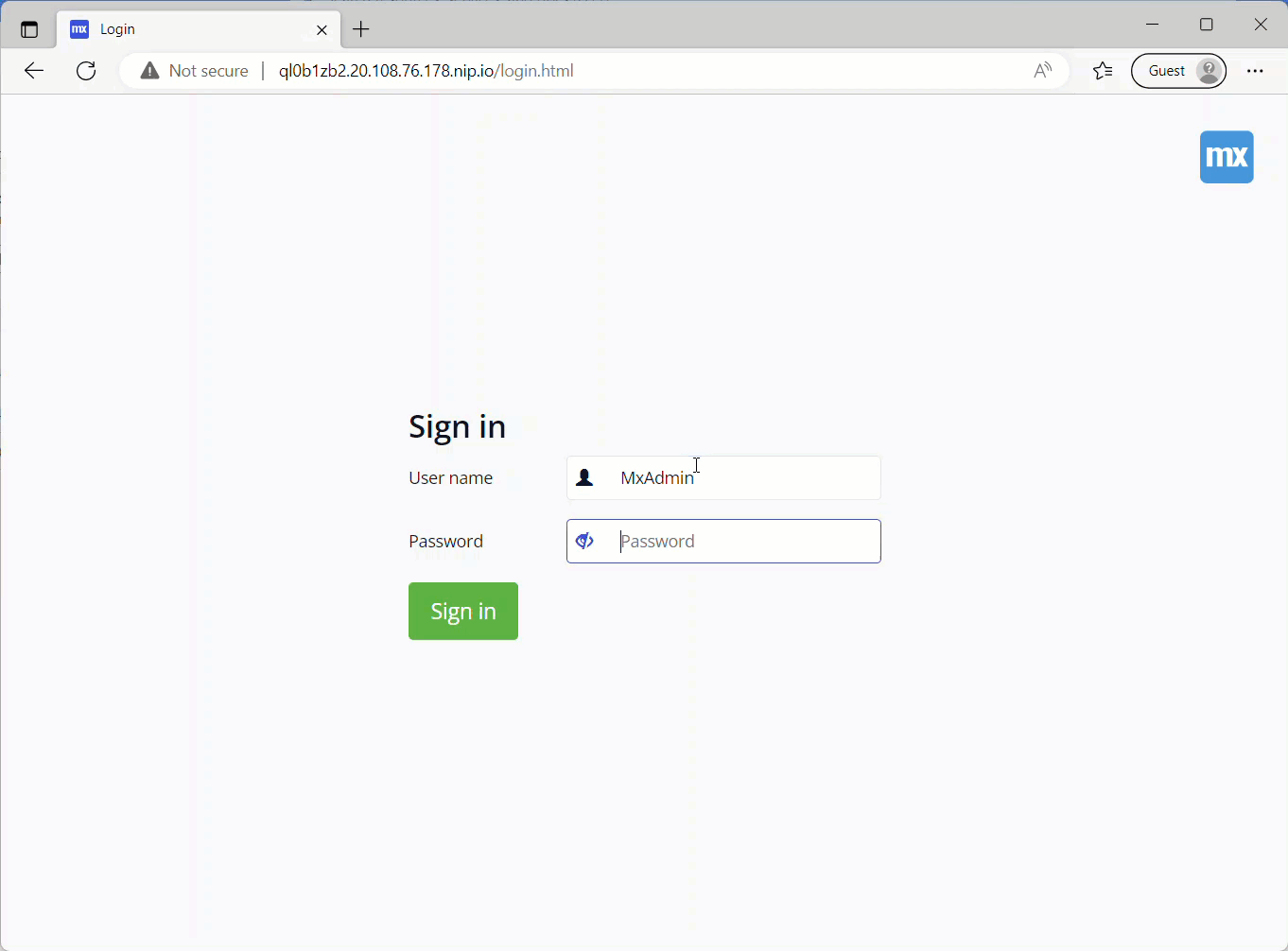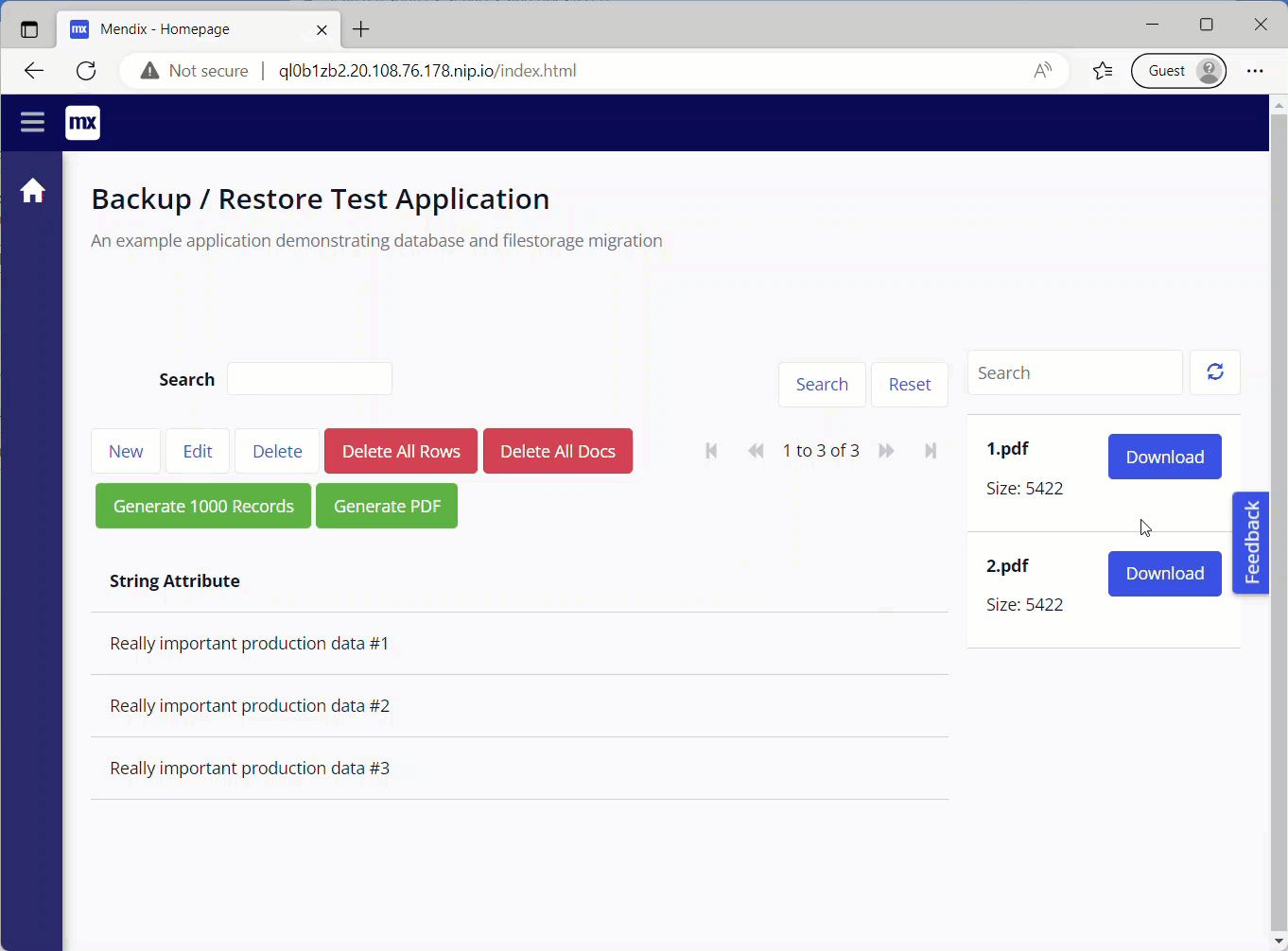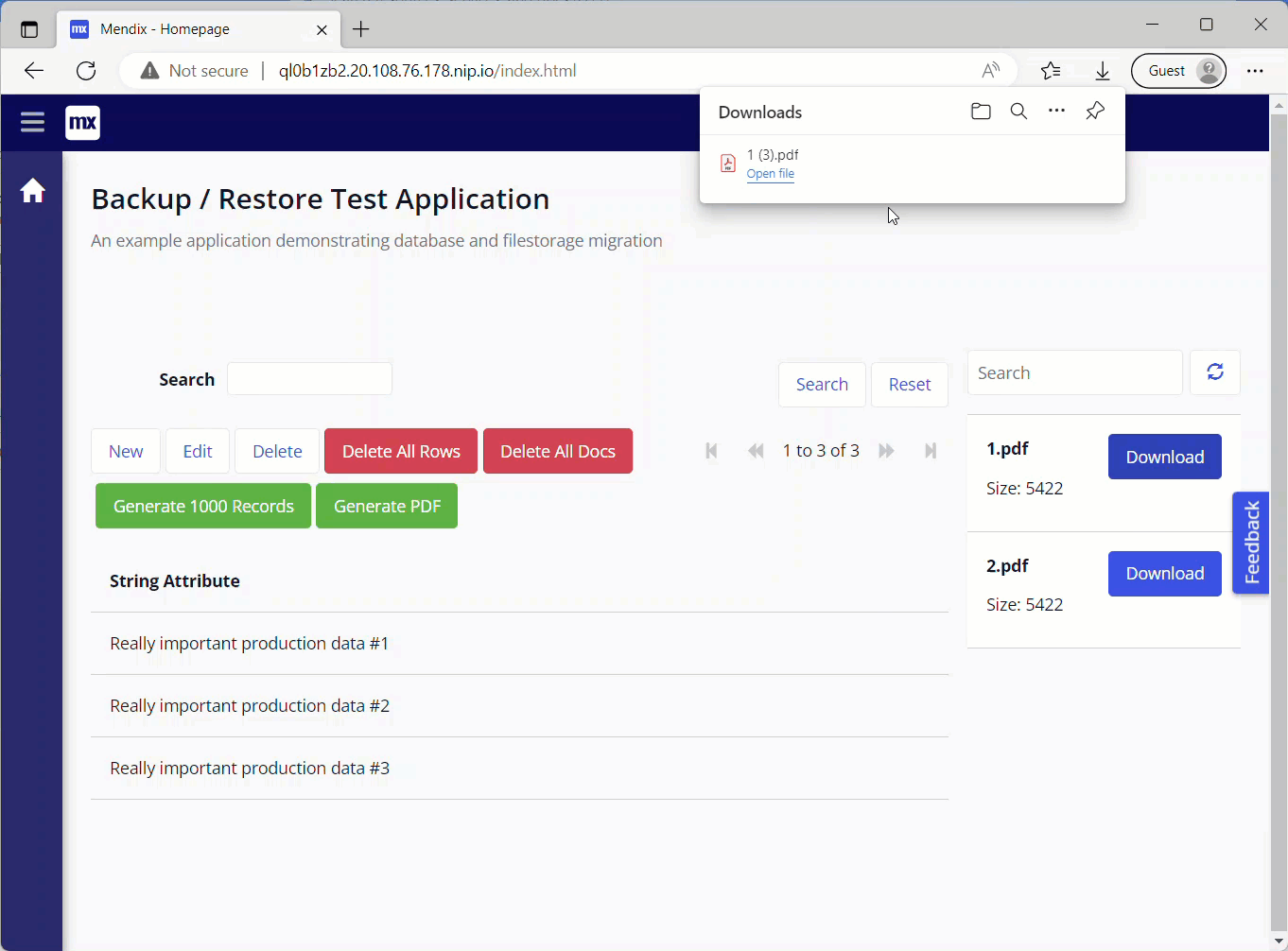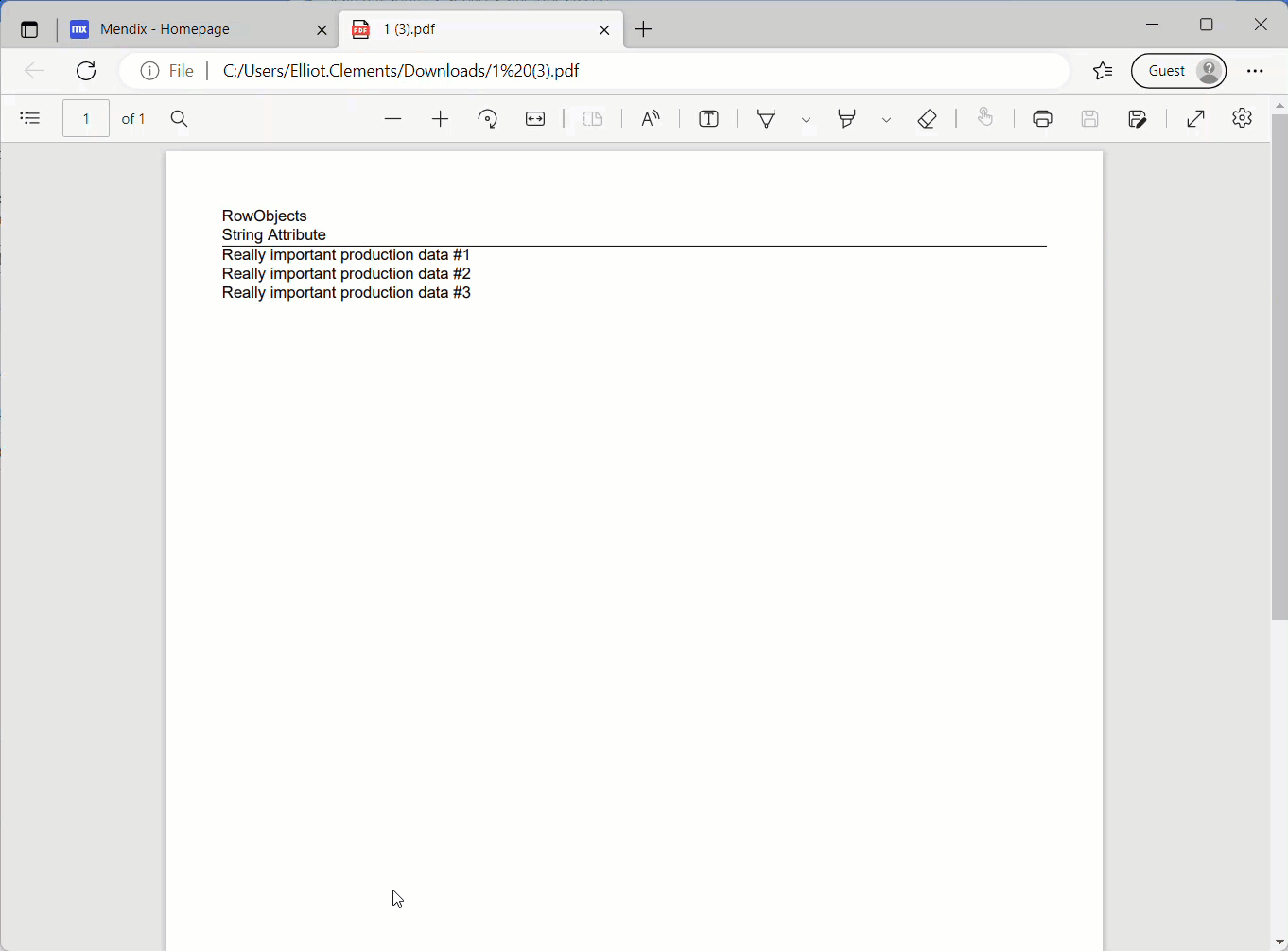
La migration des données a été un succès.
Emballer
Lors de la manipulation de données de production réelles, il est important d'exécuter une activité de nettoyage après la migration pour garantir la sécurité de ces données. Cela peut inclure :
- Suppression des téléchargements locaux des sauvegardes de production
- Destruction de toutes les bases de données temporaires
- Suppression des paramètres d'exécution personnalisés sur l'environnement cible
Mots de clôture
Il existe de nombreuses combinaisons de migrations, configurations et conceptions d'infrastructures potentielles, et il m'est impossible de les couvrir toutes dans un seul article. J'ai spécifiquement abordé un scénario complexe que vous pouvez adapter en utilisant les mêmes techniques à votre propre scénario de migration de données.
Approches alternatives
- Migration entre Mx4PC vers Mx4PC ou Mendix Du Cloud à Mx4PC avec une base de données PG ? Vous pouvez utiliser le nouveau Outil de migration de données vers un cloud privé (actuellement en avant-première au moment de la rédaction).
- Vous avez besoin d'un hôte bastion, vous pouvez créer une machine virtuelle Windows avec une installation locale de Postgres et utiliser le Mendix Console de service pour migrer la base de données vers votre cible.
Allez le migrer !